Modern websites, especially those relying on JavaScript for dynamic content, pose challenges for traditional web scraping methods. Enter Selenium, a powerful web scraping library that excels in handling asynchronous loading, infinite scrolling, and other dynamic elements with ease.
In this comprehensive guide, we'll explore why Selenium is the go-to choice for such scenarios and provide a step-by-step tutorial on building a Selenium web scraper using Python.
What is Python Web Scraping with Selenium?
Selenium is a web scraping library that empowers users to control a headless browser programmatically. This means you can open websites, navigate through pages, interact with JavaScript-based elements, and extract valuable data for further analysis or use.
As websites increasingly adopt client-side rendering through JavaScript to enhance user interactions, traditional scraping tools like Requests struggle with lazy loading and browser fingerprinting. Selenium steps in to imitate human behavior, significantly improving the success rate of data extraction.
Why Choose Selenium for Web Scraping?
Selenium's popularity for web scraping stems from its versatile features:
- JavaScript Rendering: Selenium excels at rendering JavaScript, making it indispensable for scraping websites heavily reliant on this technology.
- Cross-browser Support: Selenium can emulate major browsers such as Chrome, Firefox, and Microsoft Edge, ensuring compatibility with a wide range of websites.
- Programming Language Support: Selenium is flexible, supporting multiple programming languages like Python, Java, Ruby, and C#.
- User Behavior Emulation: Mimic human interaction with web pages—click buttons, fill out forms, submit data, scroll, and navigate seamlessly.
- CAPTCHA Handling: Selenium can tackle CAPTCHAs by displaying them in the browser, allowing manual resolution or integration with third-party services for automation.
- Fingerprint Prevention: Utilize Selenium packages like selenium-stealth to hide your digital fingerprint, preventing detection and enhancing privacy.
- Community Support: Selenium boasts a large and active community, ensuring ample resources, tutorials, and plugins to enhance your web scraping experience.
While Selenium shines in handling complex, dynamic websites, it might not be the most efficient choice for simple scraping tasks or static sites. Libraries like BeautifulSoup or Requests could be more suitable in such cases.
Additionally, headless libraries like Puppeteer may be considered for their resource efficiency. Nevertheless, when tackling intricate scenarios, Selenium stands out as a reliable and powerful tool.
Also see: The 7 Best Programming Languages for Effective Web Scraping 2024
Preparing to Build a Selenium Web Scraper
1. Project Conceptualization:
- Language Choice: While several languages are compatible with Selenium, Python is often recommended for its ease of use and suitability for a wide range of projects.
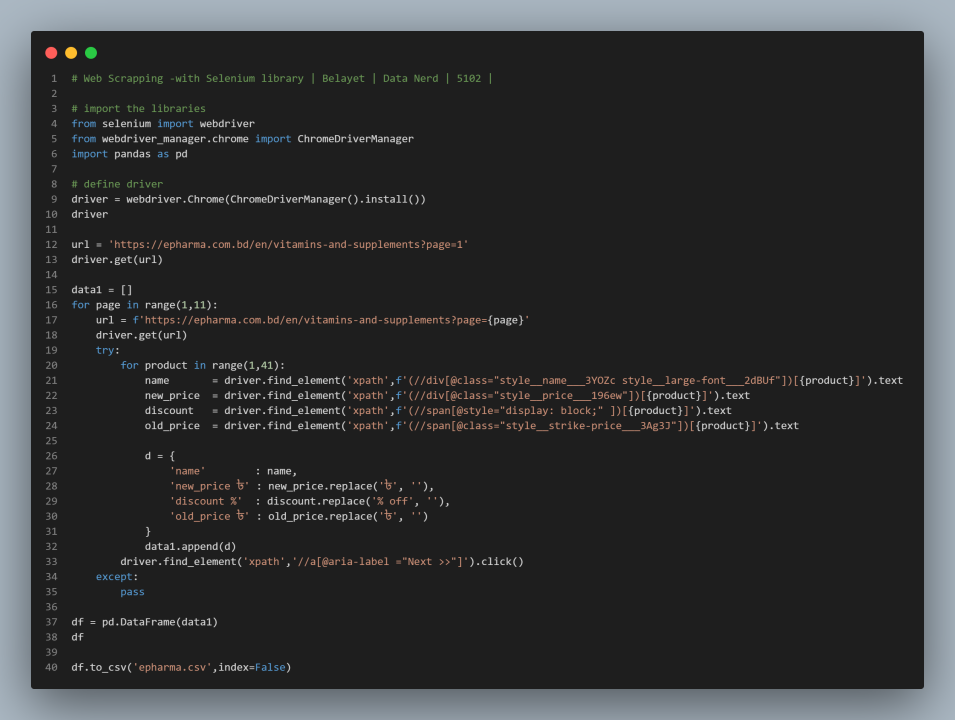
- Library Selection: Selenium provides its own packages for all stages of web scraping, eliminating the need for additional libraries.
- Project Ideas: One can start with practice websites specifically designed for scraping, then progress to real-world applications like tracking flight prices.
2. Web Scraping Ethics and Legalities:
- Adherence to website terms of service is crucial, especially avoiding scraping behind logins.
- Awareness of potential challenges like CAPTCHAs, IP bans, and structural website changes is important.
Also see: Is web scraping unethical?
3. Utilizing Proxy Servers:
- Using multiple IP addresses, preferably through paid proxy services, is recommended for avoiding detection.
- Residential proxies are preferred due to their authenticity and the possibility of sticky sessions.
Selenium Web Scraping Tutorial
In the realm of web scraping, mastery often begins with understanding and harnessing the power of Selenium.
In this step-by-step tutorial, we'll embark on a journey to scrape valuable content from two dynamic URLs on quotes.toscrape.com.
What sets this tutorial apart is its focus on handling JavaScript-generated content (http://quotes.toscrape.com/js/) and dealing with delays in rendering (http://quotes.toscrape.com/js-delayed/).
A crucial skill when the digital landscape presents challenges such as slow-loading pages or the need to wait for specific conditions before extracting data.
Prerequisites
Before delving into the Selenium magic, ensure you have the following prerequisites in place:
- Python 3: Make sure your system boasts the latest Python installation. If not, head to the official Python website at python.org for a seamless download.
- Selenium: Install the Selenium package using pip. Open your command prompt or terminal and run the command
pip install selenium. - Chrome WebDriver: Download the Chrome WebDriver corresponding to your Chrome browser. This essential component will seamlessly integrate with Selenium, allowing you to navigate the web effortlessly.
Importing the Libraries
The journey commences with the importation of the necessary libraries. Follow these steps to set the stage for your Selenium script.
# Step 1: Import Webdriver from the Selenium module
from selenium import webdriver
# Step 2: Import the web driver using the By selector module for simplified element selection
from selenium.webdriver.common.by import By
# Step 3: Import WebDriverWait and expected_conditions for efficient pausing of the scraper
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
# Step 4: Don't forget to import the CSV module for handling data
import csv
Setting the Stage for Scraping
With the groundwork laid, let's set up global variables and identify the elements crucial for our web scraping endeavor.
# Define the URL to be scraped and set a timeout to prevent scraper failure
url = 'http://quotes.toscrape.com/js/'
timeout = 10 # seconds
# Initialize an empty list to store the scraped quotes
output = []
Navigating the Elements
The heart of web scraping lies in identifying and capturing the right elements. Follow these steps to extract the desired content:
1. Inspect the Page Source: Right-click anywhere on the page and scrutinize the source code. This will guide you in selecting the relevant elements.
2. Locate Quote Elements: Use the Selenium find_elements method to locate all quote class objects.
quotes = driver.find_elements(By.CLASS_NAME, 'quote')
3. Extract Text and Author Information:
for quote in quotes:
text = quote.find_element(By.CLASS_NAME, 'text').text
author = quote.find_element(By.CLASS_NAME, 'author').text
4. Extract Tags:
tags = []
for tag in quote.find_elements(By.CLASS_NAME, 'tag'):
tags.append(tag.text)
5. Append to Output List:
output.append({
'author': author,
'text': text,
'tags': tags,
})
Master these steps, and you're well on your way to conquering dynamic web scraping challenges using Selenium. Stay tuned for more insights and advanced techniques in the ever-evolving world of web data extraction.
Scraping Dynamic Web Pages with Python Selenium

Step 1: Set up Chromium Browser with Selenium: Initialize Chromium browser using Selenium.
def prepare_browser():
# Initializing Chrome options
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
return driver
selenium_stealth or proxies if necessary.Step 2: Write the Main Function: Write a function to manage the overall process, including setting up the browser, scraping data, and printing the output.
def main():
driver = prepare_browser()
scrape(url, driver)
driver.quit()
print(output)
if __name__ == '__main__':
main()
Step 3: Implement Scraping Function:Implement a function to navigate to the specified URL, extract relevant information from the page, and store it in an output structure.
def scrape(url, driver):
driver.get(url)
quotes = driver.find_elements(By.CLASS_NAME, 'quote')
for quote in quotes:
text = quote.find_element(By.CLASS_NAME, 'text').text
print(f'Text: {text}')
author = quote.find_element(By.CLASS_NAME, 'author').text
print(f'Author: {author}')
tags = []
for tag in quote.find_elements(By.CLASS_NAME, 'tag'):
tags.append(tag.text)
print(tags)
output.append({
'author': author,
'text': text,
'tags': tags,
})
# This will open the browser, scrape one page, and print the output.
Scraping Multiple Pages
Step 1: Find the Link to the Next Page: Locate the link to the next page for handling pagination.
elem_next = driver.find_element(By.CLASS_NAME, 'next').find_element(By.TAG_NAME, 'a')
next_url = elem_next.get_attribute("href")
scrape(next_url, driver)
Step 2: Handle Pagination: Use a try-except block to navigate to the next page, avoiding crashes when the next button is not found.
try:
elem_next = driver.find_element(By.CLASS_NAME, 'next').find_element(By.TAG_NAME, 'a')
next_url = elem_next.get_attribute("href")
scrape(next_url, driver)
except:
print('Next button not found. Quitting.')
Wrap the code in a try-except block to handle pagination and prevent crashes on the last page.
Scraping and Waiting for Page Load
When working with web scraping, it's crucial to account for delays caused by elements loading or generated by JavaScript. In such cases, utilizing the Selenium WebDriverWait class becomes essential to ensure that the necessary elements are present before parsing the page. Here's a step-by-step guide using Python:
Step 1: Implementing WebDriverWait
WebDriverWait(driver, timeout).until(
expected_conditions.presence_of_element_located((By.CLASS_NAME, 'quote'))
)Step 2: Handling Timeout with Retry
You can enhance the script by implementing a try-except block to handle timeouts or absence of elements. This allows you to retry the same request if needed.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def scrape(url, driver):
driver.get(url)
print(f"Opened: {driver.current_url}")
try:
WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((By.CLASS_NAME, 'quote'))
)
# Parsing elements after they are loaded
quotes = driver.find_elements(By.CLASS_NAME, 'quote')
for quote in quotes:
text = quote.find_element(By.CLASS_NAME, 'text').text
print(f'Text: {text}')
author = quote.find_element(By.CLASS_NAME, 'author').text
print(f'Author: {author}')
tags = [tag.text for tag in quote.find_elements(By.CLASS_NAME, 'tag')]
print(tags)
output.append({
'author': author,
'text': text,
'tags': tags,
})
try:
elem_next = driver.find_element(By.CLASS_NAME, 'next').find_element(By.TAG_NAME, 'a')
next_url = elem_next.get_attribute("href")
scrape(next_url, driver)
except:
print('Next button not found. Quitting.')
except:
print('Timed out.')
Saving Output to CSV
Finally, you can store the scraped data in a CSV file. Add the following lines to the main() function:
import csv
field_names = ['author', 'text', 'tags']
output_filename = 'quotes.csv'
with open(output_filename, 'w', newline='', encoding='utf-8') as f_out:
writer = csv.DictWriter(f_out, fieldnames=field_names)
writer.writeheader()
writer.writerows(output)
This code creates a CSV file, writes the header, and populates the file with dictionary objects from the output list. Adjust the field_names and output_filename as needed.
Advanced Web Scraping Techniques
Dealing with AJAX and JavaScript
Navigating websites that employ AJAX and JavaScript can be akin to traversing a maze. Selenium equips you with the tools to expertly handle these dynamic elements:
- Understanding Asynchronous Requests: AJAX relies on asynchronous requests. Learn how to synchronize your script with the dynamic loading of content.
- Leveraging Explicit and Implicit Waits: Selenium provides powerful tools to wait patiently for elements to appear. Uncover the secrets of explicit and implicit waits.
- Interacting with Dynamic Elements: Dynamic content often hides valuable information. Learn how to locate and interact with these elusive elements using Selenium.
Cookies and Sessions: Beyond the Sweet Treats

Cookies aren't just for satisfying your sweet tooth; they play a crucial role in web scraping too. Let's dive into the realm of cookies and sessions.
- Handling Cookies: Websites use cookies to store information. Discover how to manipulate and use cookies to your advantage without leaving a crumb trail.
- Maintaining Sessions: Long scraping sessions require a way to persist data. Explore how to keep sessions alive and avoid being kicked out by websites.
Capturing Screenshots and Scraping Images
Sometimes, a picture is worth a thousand words. Learn how to capture the essence of a webpage with screenshots and extract valuable data from images.
Extracting Image Data: Unearth the techniques to extract information from images. From OCR (Optical Character Recognition) to analyzing image metadata, the possibilities are vast.
Handling Frames and iframes: The Web's Puzzle Pieces
Webpages often resemble a complex puzzle, with frames and iframes acting as essential pieces. Let's decode these elements with Selenium.
Extracting Data from iframes: Peek inside iframes to extract valuable nuggets of information. Selenium allows you to traverse these encapsulated spaces with finesse.
Conclusion
In conclusion, Selenium stands as the stalwart ally in the dynamic landscape of web scraping, excelling in handling modern websites with JavaScript-heavy content.
Its versatility, cross-browser support, and ability to mimic human behavior make it a go-to choice for complex scraping tasks. However, it's crucial to acknowledge its optimal use cases and consider alternatives for simpler tasks.
The provided tutorial equips both beginners and experts with practical insights, covering project conceptualization, ethical considerations, and advanced techniques.
Frequently Asked Questions
Is Selenium the only tool for web scraping with Python, or are there alternatives?
While Selenium is a powerful tool for handling dynamic content, other libraries like BeautifulSoup and Requests are more suitable for simple scraping tasks or static websites. Additionally, headless browsers like Puppeteer can be considered for resource efficiency. The choice depends on the complexity of the scraping task.
How does Selenium handle challenges like CAPTCHAs and browser fingerprinting?
Selenium can handle CAPTCHAs by displaying them in the browser, allowing manual resolution or integration with third-party services for automation. To address browser fingerprinting, packages like selenium-stealth can be used to hide your digital fingerprint, enhancing privacy and reducing the risk of detection.
Are there any ethical considerations or legal implications when using Selenium for web scraping?
Absolutely. Adherence to website terms of service is crucial, especially avoiding scraping behind logins. Awareness of potential challenges like CAPTCHAs, IP bans, and structural changes on websites is important. It's essential to respect the ethical guidelines of web scraping and be aware of the legal implications.
Can Selenium handle websites with AJAX and JavaScript-based dynamic content?
Yes, one of Selenium's strengths is its ability to handle websites heavily reliant on JavaScript. It can synchronize with the asynchronous requests of AJAX, leverage explicit and implicit waits to handle dynamic loading, and interact seamlessly with dynamic elements on the page.
How can I prevent my IP address from being banned while web scraping with Selenium?
To avoid IP bans, it's recommended to use multiple IP addresses, preferably through paid proxy services. Residential proxies are preferred for their authenticity and the possibility of sticky sessions. Rotating IP addresses and being mindful of the frequency and pattern of requests can help maintain a low profile and reduce the risk of detection.
For further reading, you might be interested in the following: