
Web scraping is the automated extraction of data from websites, often used to gather information for a variety of purposes such as price comparison, sentiment analysis, or data aggregation. While web scraping can be beneficial in some instances, unauthorized web scraping can negatively impact website performance, steal sensitive information, and violate copyright and data protection laws. In this blog post, we will explore the importance of preventing unauthorized web scraping and discuss various strategies to protect your website and data.
General Data Protection Regulations (GDPR) for European Union: Official resource
California Consumer Privacy Act (CCPA) for California, USA: Official resource
Understanding Web Scraping
Definition and purpose of web scraping
Web scraping is a technique that involves extracting information from websites using automated tools or scripts, typically for data analysis or other data-driven applications. This process can be useful for businesses and researchers looking to gather specific information across multiple websites quickly and efficiently.
Common tools and techniques used for web scraping
There are many web scraping tools available, ranging from simple browser extensions to more complex libraries and frameworks. Some popular web scraping tools include Beautiful Soup, Scrapy, and Selenium. These tools use a combination of techniques, such as making HTTP requests, parsing HTML, and navigating the Document Object Model (DOM), to extract data from websites.
Legal and ethical aspects of web scraping
While web scraping can provide valuable data, it can also raise legal and ethical concerns. Issues such as copyright infringement, data privacy, and violation of terms of service can arise from unauthorized web scraping. It's essential to be aware of these concerns and ensure that your web scraping activities are conducted ethically and legally. We have a detailed blog post about is web scraping ethical or not?
Common Signs of Web Scraping
Sudden increase in server load and bandwidth usage
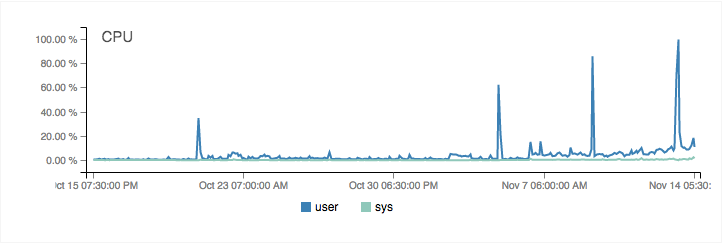
Web scraping can cause a sudden surge in server load and bandwidth usage, as scrapers may make a large number of requests in a short period. This can lead to slower website performance and increased hosting costs.
Unusual patterns of user agent strings
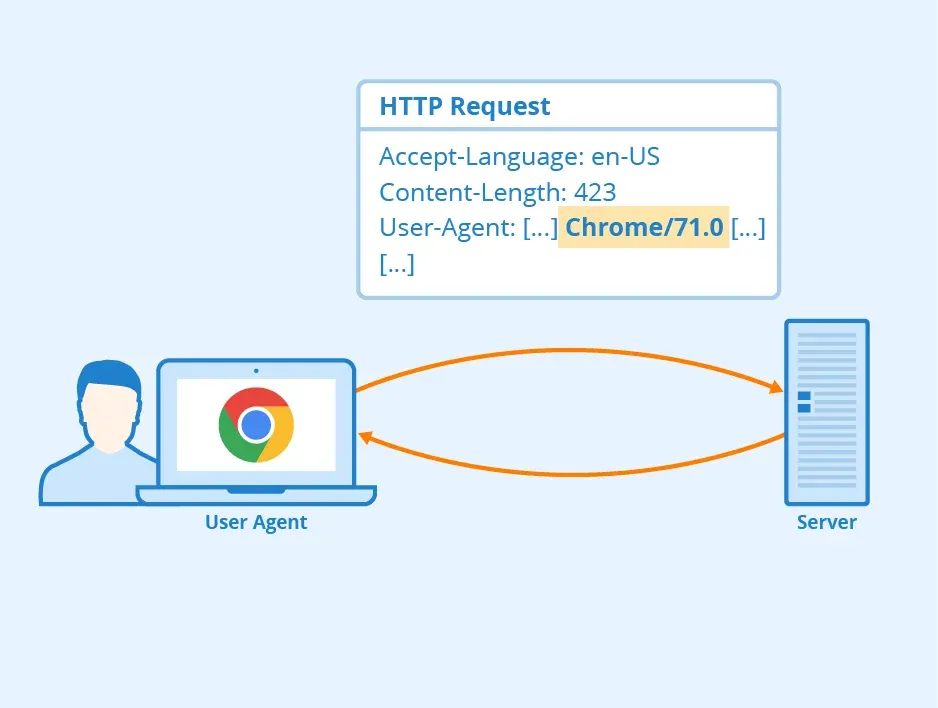
Web scrapers may use fake or unusual user agent strings to avoid detection, which can appear as an anomaly in your website's traffic logs.
Frequent and repetitive requests from the same IP addresses
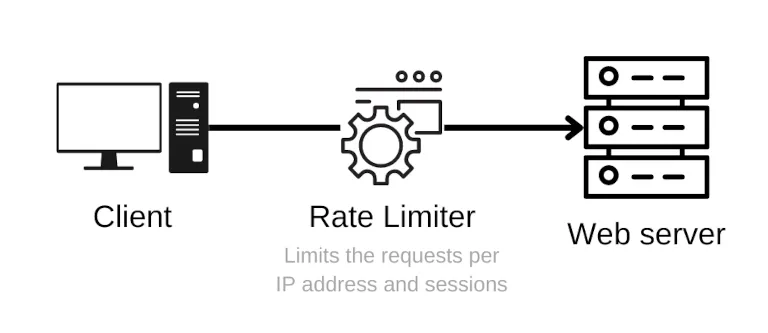
Web scrapers often make multiple requests from the same IP address, which can be a sign of unauthorized web scraping activity. You should create a rate limit for ip addresses.
Unexplained increase in page views and bounce rate

A sudden spike in page views and bounce rate may indicate that a web scraper is visiting multiple pages on your website without engaging with the content, leading to increased traffic without any corresponding user engagement.
Methods to Prevent Web Scraping
Implement rate limiting

Rate limiting restricts the number of requests that can be made to your website in a given timeframe, helping to prevent excessive web scraping. There are several rate limiting strategies:
- IP-based rate limiting: Limit the number of requests from a single IP address.
- User-based rate limiting: Limit the number of requests from a specific user or user group.
- API key rate limiting: Limit the number of requests for users with a specific API key.
Use CAPTCHA and challenge-response tests
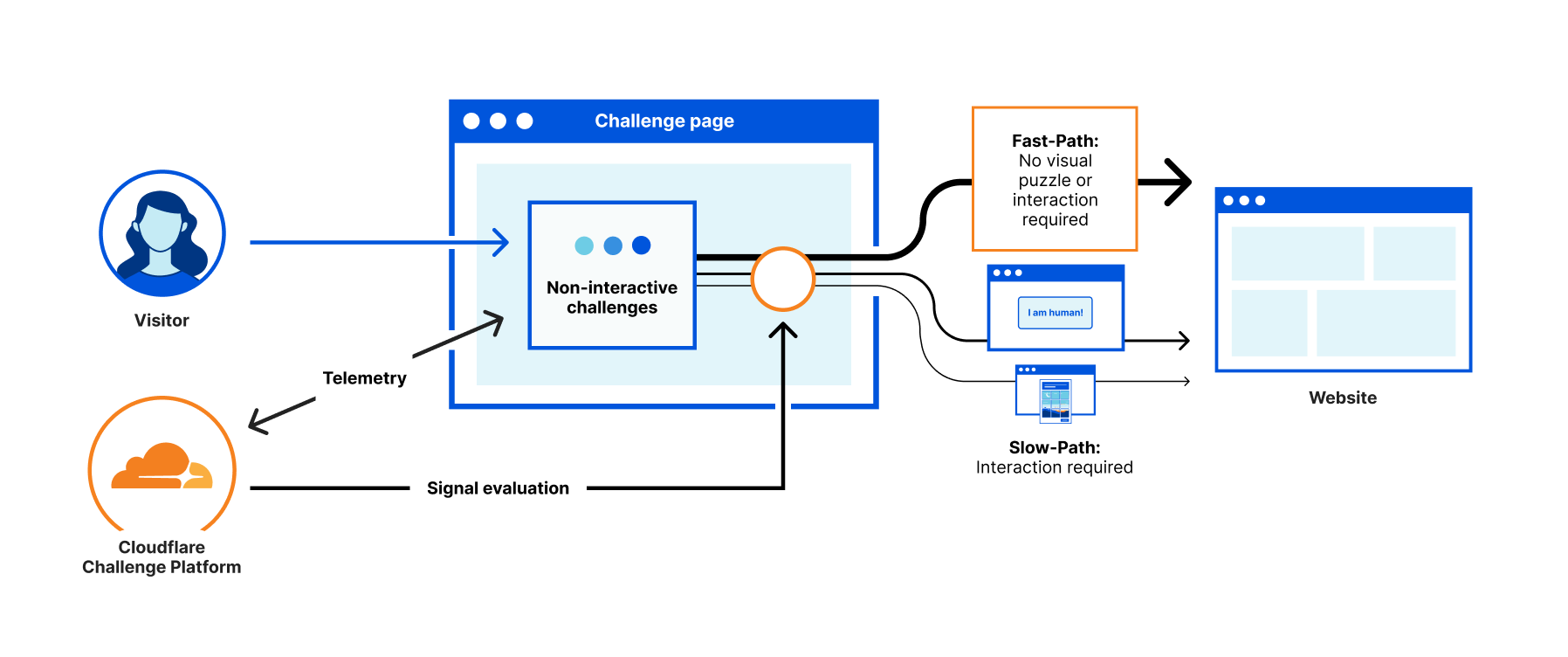
CAPTCHA tests help differentiate between human users and automated bots. Some popular CAPTCHA solutions include:
- Google reCAPTCHA: Uses advanced risk analysis to distinguish between bots and humans.
- Honeypot technique: Invisible form fields that are filled in by bots but ignored by humans.
- Custom challenge-response tests: Create your own tests, such as simple math problems or image recognition tasks.
Require user registration and authentication
Requiring users to register and authenticate themselves can deter casual web scrapers. Consider implementing:
- Social media login: Allow users to log in using their existing social media accounts.
- Two-factor authentication (2FA): Require users to provide an additional layer of verification, such as a code sent to their mobile device, for added security.
- D. Obfuscate website content and structure
- Making your website's content and structure more difficult to interpret can deter web scraping attempts:
- Dynamic HTML content: Use AJAX or other dynamic content loading techniques to make it harder for scrapers to parse your website's content.
- JavaScript rendering: Render content using JavaScript, as many web scrapers struggle to execute JavaScript code.
- Encrypted data elements: Encrypt sensitive data elements, making it more challenging for scrapers to extract useful information.
Monitor and analyze web traffic
Keeping a close eye on your website's traffic can help you identify and respond to potential web scraping attempts:
- Web analytics tools: Use tools like Google Analytics to monitor traffic patterns and identify potential web scraping activity.
- Intrusion detection systems (IDS): Implement IDS to detect and respond to suspicious traffic patterns and potential security threats.
- User behavior analysis: Analyze user behavior to identify anomalies and potential web scraping activity.
Choosing a Web Scraping Prevention Solution

Features to consider
When selecting a web scraping prevention solution, consider the following features:
- Ease of integration: Choose a solution that can be easily integrated into your existing website infrastructure.
- Scalability and flexibility: Opt for a solution that can scale to meet your website's growing needs and adapt to new scraping techniques.
- Cost-effectiveness: Evaluate the cost of the solution against the potential losses caused by unauthorized web scraping.
Examples of web scraping prevention services
Several services specialize in web scraping prevention. Some popular examples include:
- Cloudflare: Offers a variety of security features, including rate limiting, bot management, and DDoS protection.
- Imperva Incapsula: Provides a comprehensive security solution that includes anti-bot protection, rate limiting, and website performance optimization.
- Akamai: Offers a range of security solutions, including bot detection and mitigation, rate limiting, and content delivery optimization.
Evaluate the trade-offs between user experience and security
While implementing web scraping prevention measures is essential, it's crucial to balance security with user experience. Ensure that the measures you adopt do not negatively impact legitimate users' ability to access and interact with your website.
Frequently Asked Questions (FAQ)
Is web scraping always illegal or unethical?
Web scraping is not inherently illegal or unethical, but it can become so if it violates a website's terms of service, infringes on copyright, or compromises user privacy. Always ensure that you have permission to scrape a website and that you follow ethical guidelines when conducting web scraping activities.
Can I completely stop web scraping on my website?
While it is challenging to prevent all web scraping attempts, implementing the strategies outlined in this blog post can significantly reduce unauthorized scraping. Keep in mind that determined scrapers may still find ways to bypass your defenses, so continuously monitoring your website's traffic and updating your security measures is essential.
How can I identify if my website is being scraped?
Common signs of web scraping include a sudden increase in server load and bandwidth usage, unusual patterns of user agent strings, frequent and repetitive requests from the same IP addresses, and an unexplained increase in pageviews and bounce rate. Monitoring your website traffic using analytics tools can help you identify potential scraping activity.
Will implementing web scraping prevention measures affect my website's performance?
Some web scraping prevention measures may have a minor impact on your website's performance, but the benefits of protecting your data and maintaining your website's integrity generally outweigh any potential downsides. Be sure to evaluate the trade-offs between security and user experience when implementing prevention measures.
Can I use web scraping prevention techniques to protect my API?
Yes, many of the web scraping prevention techniques discussed in this blog post can also be applied to protect your API. Rate limiting, authentication, and monitoring API usage can help prevent unauthorized access and excessive data extraction.
What should I do if I discover unauthorized web scraping on my website?
If you identify unauthorized web scraping activity on your website, you should first implement the prevention measures outlined in this blog post. Additionally, you may wish to consult with legal professionals to understand your options for taking action against those responsible for the unauthorized scraping.
Conclusion
Preventing unauthorized web scraping is vital for protecting your website's performance, data, and overall user experience. By understanding web scraping techniques and implementing a combination of rate limiting, CAPTCHA tests, user authentication, content obfuscation, and traffic monitoring, you can effectively safeguard your website against unauthorized data extraction. It's also essential to choose a web scraping prevention solution that meets your specific needs and balances security with user experience. Stay informed on web scraping trends and continue to adapt your prevention strategies as needed, ensuring the long-term protection of your website and data.