

In the ever-evolving landscape of e-commerce, Amazon stands out as a global giant. To gain valuable insights into specific products and categories, scraping Amazon product data has become a crucial practice. In this article, we'll walk you through the process step by step, highlighting its benefits and various use cases.
Understanding the Essence of Scraping Amazon Product Data
Scraping Amazon product data involves extracting information from the platform and transferring it to other formats, such as spreadsheets. Whether for personal or business use, this process can yield a wealth of information, including product details, pricing, seller ratings, and customer reviews.

Here are some key considerations for effective Amazon product data scraping:
- Adherence to Terms of Service: Before diving into scraping activities, it's crucial to review Amazon's terms of service. Ethical guidelines must be followed to ensure compliance and avoid any legal complications.
- Responsible Scraping Practices: Aggressive scraping can have consequences. It's essential to strike a balance between obtaining the data you need and respecting intellectual property rights and user privacy. This approach aligns with regulatory requirements and ethical standards.
- User-Agent Header Implementation: To reduce the risk of detection and flagging by anti-scraping mechanisms, incorporating a User-Agent header in HTTP requests is advisable. This simple measure helps maintain a low profile during scraping activities.
- Proxy Servers for Anonymity: To prevent being blocked during data scraping, the use of proxy servers enhances anonymity. This not only reduces the risk of detection but also allows for a smoother and uninterrupted scraping process.
- Strategies for CAPTCHAs and JavaScript Challenges: Dealing with CAPTCHAs and JavaScript challenges is part of the scraping landscape. Additional services may be necessary to handle these obstacles effectively. Implementing strategies to navigate through these challenges ensures a more robust scraping mechanism.
- Regular Script Updates: Manual scraping requires adapting to changes in website structure. Regularly updating your script is essential to align with modifications on the Amazon platform, ensuring the continued accuracy of the scraped data.

How to Scrape Amazon Product Data?
To scrape Amazon product data, you can set up a web scraping environment in Python, inspect the web page, write relevant scripts, and handle pagination. If you prefer a quicker solution, you can use tools like Bright Data, Oxylabs, or Apify for scraping. In this guide, we'll explain how to use Bright Data's Scraping Browser.
Follow these steps after creating your account and signing in:
Step 1: Set Up Scraping Browser
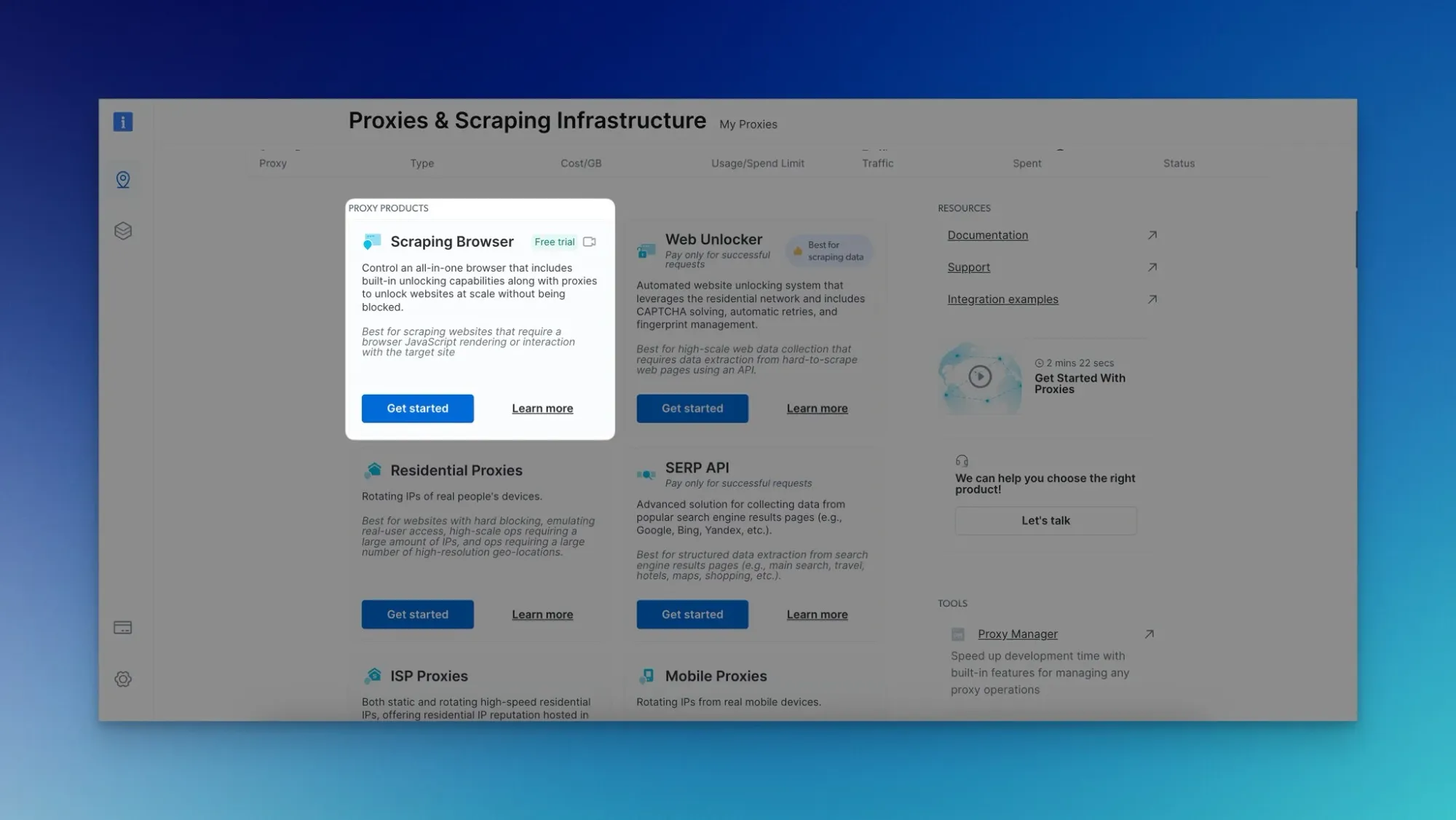
- Navigate to the "Proxies & Scraping Infrastructure" page.
- Click "Get Started" in the "Scraping Browser" section.
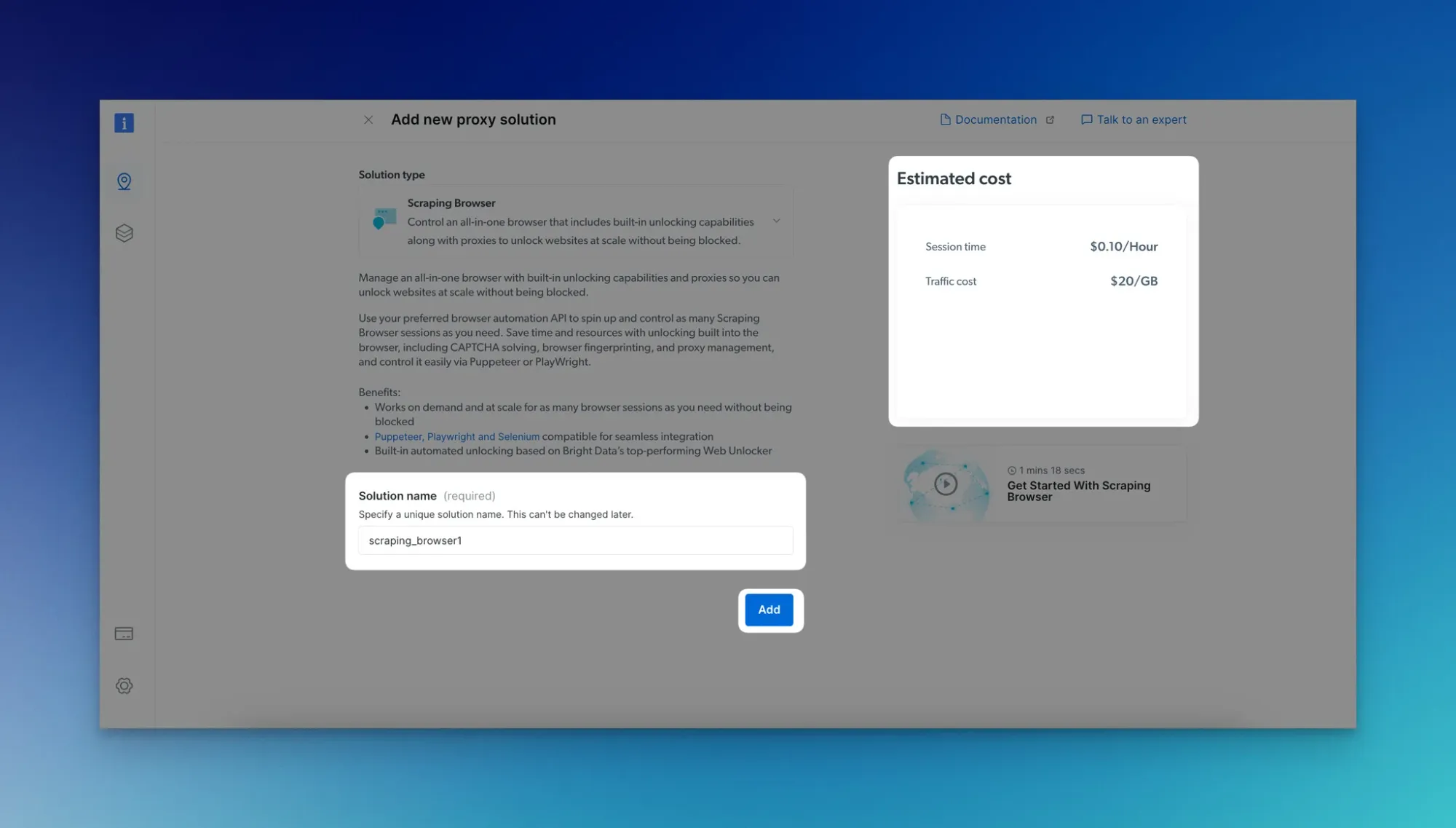
- Enter a name, and click "Add." Take note of the credentials.
Step 2: Access Parameters
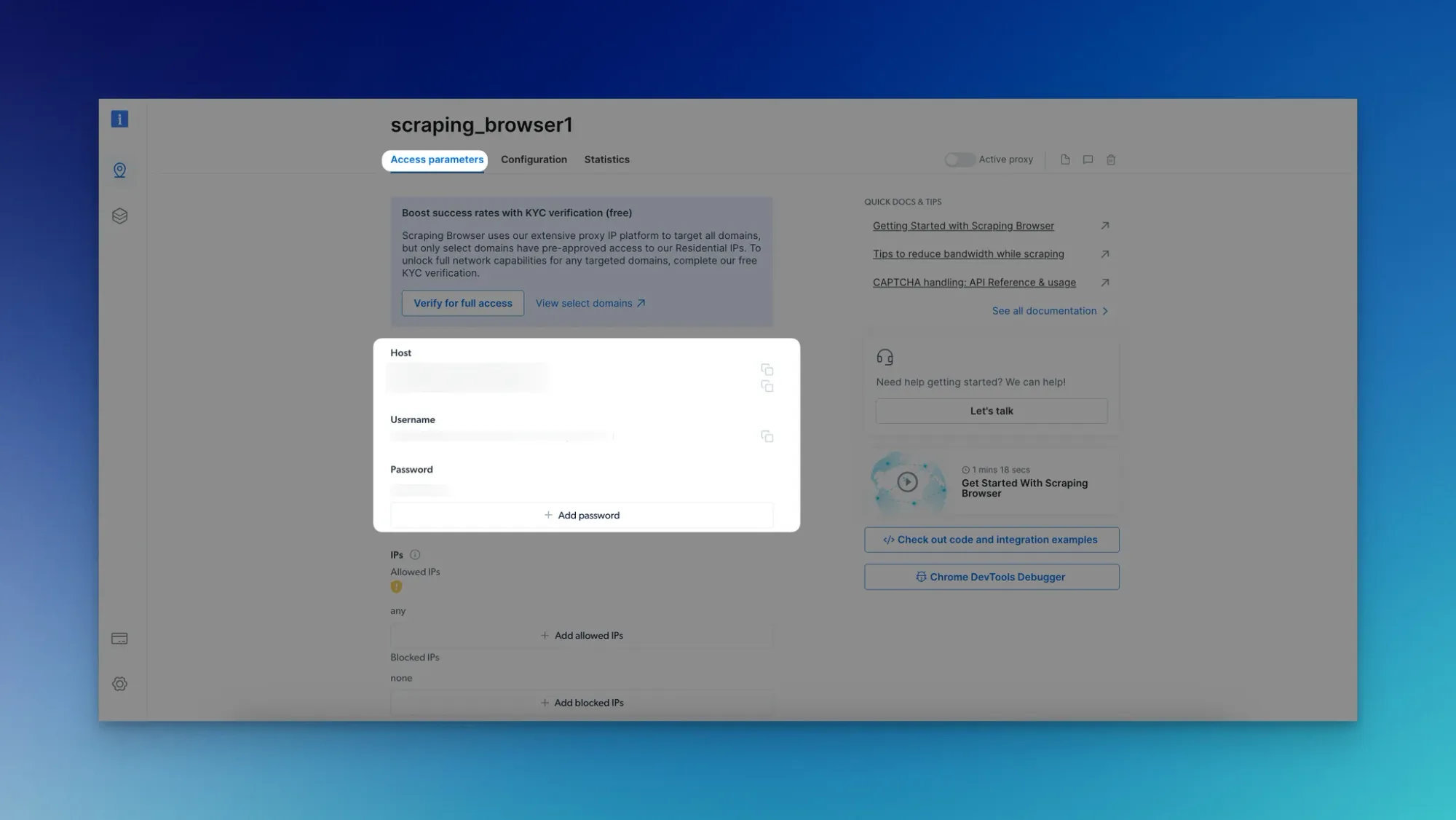
- Go to the "Access parameters" page to get the host, username, and password details.
- Keep these credentials secure.
Step 3: Integration
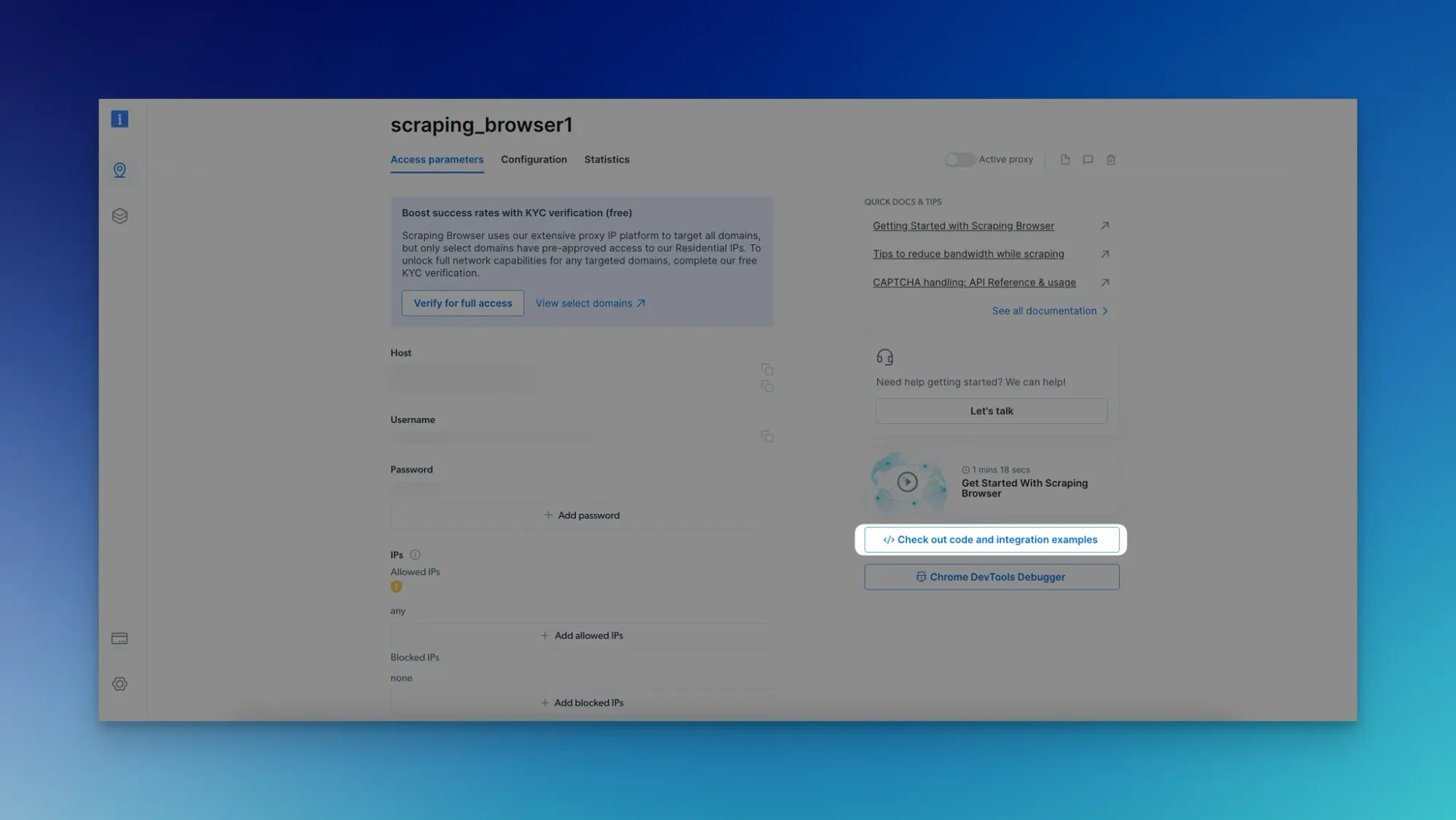
- Click "Check out code and integration examples."
- Choose your preferred language (e.g., Node.js, Python) and browser navigation library (e.g., Puppeteer).
- Install the required library (e.g., Puppeteer) via npm.
Step 4: Run Script
- Use the provided script example and substitute your credentials, zone, and target URL.
- Run the script using
node script.js.
const puppeteer = require('puppeteer-core');
const AUTH = 'USER:PASS';
const SBR_WS_ENDPOINT = `wss://${AUTH}@brd.superproxy.io:9222`;
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
console.log('Connected! Navigating...');
const page = await browser.newPage();
await page.goto('https://example.com', { timeout: 2 * 60 * 1000 });
console.log('Taking screenshot to page.png');
await page.screenshot({ path: './page.png', fullPage: true });
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
// CAPTCHA solving: If you know you are likely to encounter a CAPTCHA on your target page, add the following few lines of code to get the status of Scraping Browser's automatic CAPTCHA solver
// Note 1: If no captcha was found, it will return not_detected status after detectTimeout
// Note 2: Once a CAPTCHA is solved, if there is a form to submit, it will be submitted by default
// const client = await page.target().createCDPSession();
// const {status} = await client.send('Captcha.solve', {detectTimeout: 30*1000});
// console.log(`Captcha solve status: ${status}`)
} finally {
await browser.close();
}
}
if (require.main === module) {
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
}Step 5: Customize for Amazon
- Modify the script to navigate to Amazon and scrape product data.
- Adjust details based on your specific use case.
Step 6: Optional - Open DevTools
- Optionally, open DevTools for live browser session analysis.
- Use the provided code snippet to automatically initiate DevTools.
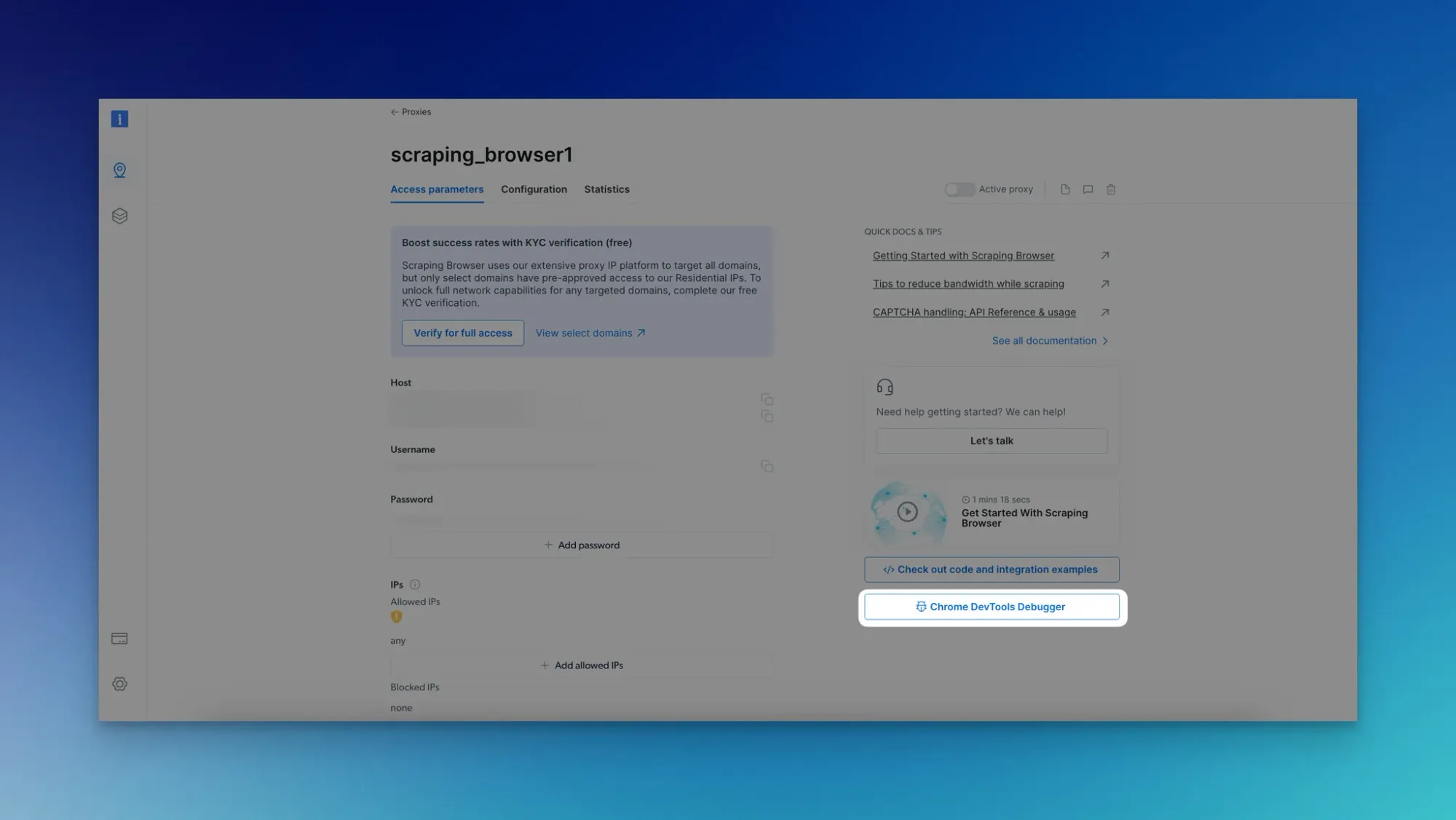
Step 7: Gather Data
- Optimize your code according to your requirements for scraping Amazon product data.
- Let Scraping Browser handle operations like CAPTCHA solving and retries automatically.
// Node.js Puppeteer - launch devtools locally
const { exec } = require('child_process');
const chromeExecutable = 'google-chrome';
const delay = ms => new Promise(resolve => setTimeout(resolve, ms));
const openDevtools = async (page, client) => {
// get current frameId
const frameId = page.mainFrame()._id;
// get URL for devtools from scraping browser
const { url: inspectUrl } = await client.send('Page.inspect', { frameId });
// open devtools URL in local chrome
exec(`"${chromeExecutable}" "${inspectUrl}"`, error => {
if (error)
throw new Error('Unable to open devtools: ' + error);
});
// wait for devtools ui to load
await delay(5000);
};
const page = await browser.newPage();
const client = await page.target().createCDPSession();
await openDevtools(page, client);
await page.goto('http://example.com');Step 8: Monitor Statistics
- Check the "Statistics" section in Scraping Browser for metrics, event logs, and access logs.
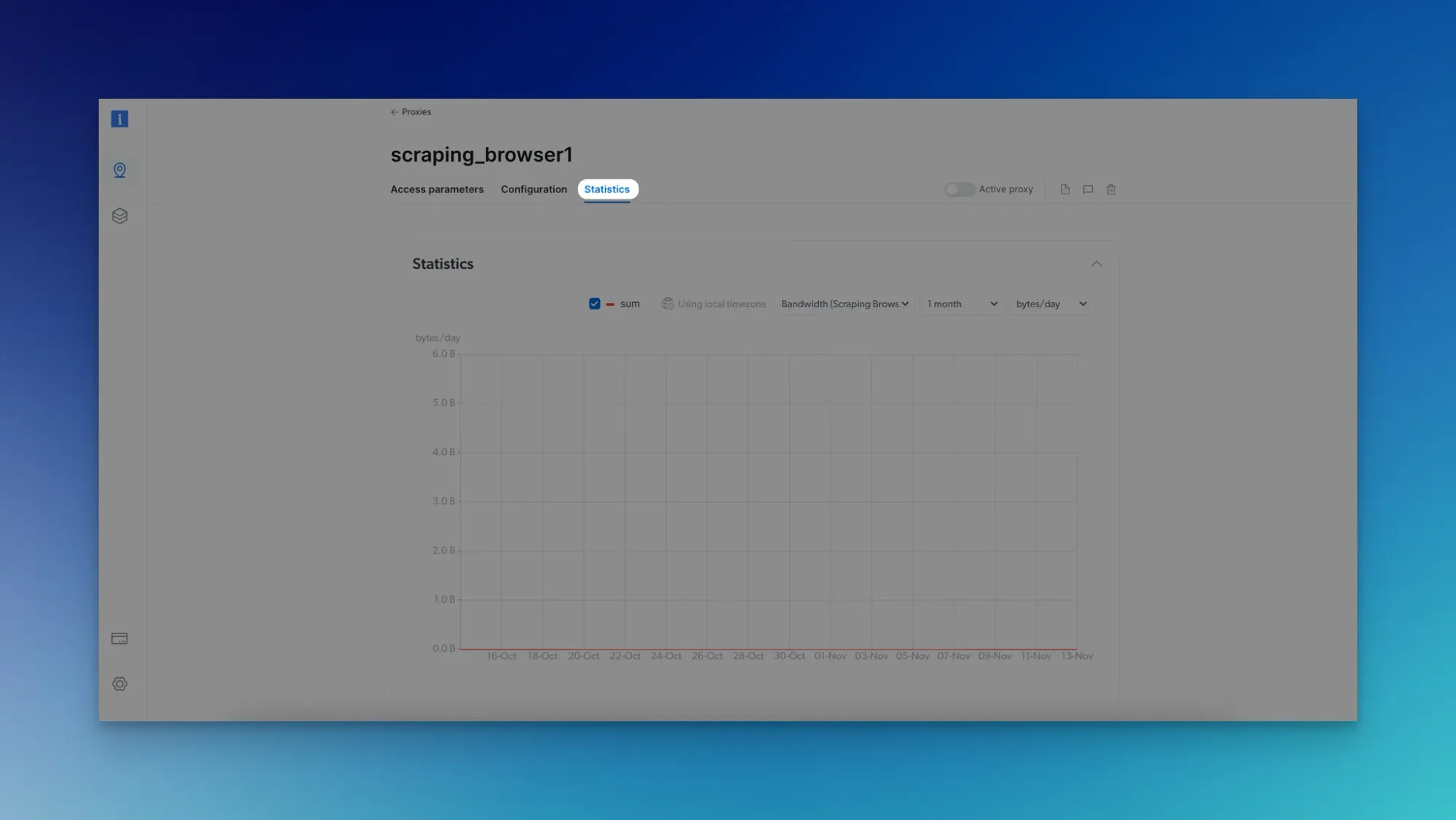
Make sure to adhere to ethical guidelines and respect the terms of service of the websites you are scraping.
Understanding the Significance of Amazon Product Data
In the realm of e-commerce, Amazon stands as a vast treasure trove of valuable product data. The information available on this platform can be harnessed for various purposes, offering insights that cater to the diverse needs of businesses and researchers alike. Let's explore some key applications of scraping Amazon product data and the myriad benefits it brings.
Usage Areas of Amazon Product Data
* In-Depth Market Studies for Researchers: Conduct comprehensive market studies and track product trends using Amazon product data, providing researchers with valuable information to understand consumer behavior within specific categories.
* Dynamic Price Monitoring for E-commerce: Implement real-time price monitoring by scraping Amazon product data, enabling e-commerce businesses to adjust pricing strategies in response to competitor pricing and market dynamics.
* Content Creation Optimization: Identify popular keywords and trending topics within Amazon product data to optimize content creation efforts, assisting content creators in developing engaging and relevant material.
* Holistic Brand Monitoring: Monitor product listings, customer reviews, and overall brand perception by leveraging scraped Amazon data, allowing brands to maintain a comprehensive view of their market presence.
* Academic Research on Consumer Behavior: Utilize scraped Amazon data for academic research, including the analysis of consumer behavior and the impact of customer reviews on purchasing decisions.
Advantages of Possessing Amazon Product Data
➡️ Informed Decision-Making Across Sectors: Leverage accurate and up-to-date Amazon product data for informed decision-making, serving various sectors such as business strategy, product lineup, and market research.
➡️ Precision in Targeted Marketing: Refine marketing strategies with valuable insights from Amazon product data, ranging from identifying popular keywords to analyzing successful advertising approaches.
➡️ Agile Competitor Strategy Adjustment: Monitor and adjust strategies effectively by gaining insights into competitors' pricing, product features, and customer reviews through scraped Amazon data.
➡️ Proactive Trend Analysis: Stay ahead of trends by utilizing Amazon product data to identify emerging products and adapt inventories accordingly, ensuring businesses meet changing customer demands.
➡️ Strategic Pricing Dynamics: Optimize pricing strategies in real-time by tracking competitor prices through scraped Amazon data, allowing businesses to maintain a competitive edge.
➡️ Product Portfolio Enhancement: Enhance existing products and introduce new offerings aligned with consumer preferences by analyzing customer reviews and market trends within Amazon product data.
➡️ Facilitating Strategic Collaborations: Form strategic partnerships and collaborations with confidence, armed with a comprehensive understanding of market positions through scraped Amazon data.
➡️ Efficient Inventory Management Practices: Optimize inventory levels, reduce carrying costs, and enhance supply chain efficiency by scraping data on product availability and sales volumes.
➡️ Insights from Customer Feedback: Extract valuable insights from customer reviews and feedback within Amazon product data, facilitating continuous improvement and customer satisfaction.
Conclusion
Scraping Amazon product data has emerged as a pivotal practice in the dynamic landscape of e-commerce, offering a wealth of insights for businesses, researchers, and individuals. However, it is crucial to approach this process with ethical considerations and adherence to the terms of service outlined by Amazon.
By following responsible scraping practices, incorporating technical strategies such as User-Agent headers and proxy servers, and staying updated with regular script maintenance, users can navigate the challenges presented by CAPTCHAs and JavaScript obstacles.
In this guide, we highlighted the process of scraping Amazon product data using Bright Data's Scraping Browser as an example. This tool and others like Oxylabs and Apify provide a quick solution for those who prefer efficiency in their scraping endeavors.
The significance of Amazon product data spans various applications, including informed decision-making, targeted marketing strategies, competitor monitoring, trend analysis, pricing optimization, product development, strategic partnerships, efficient inventory management, and customer feedback analysis. The accurate and current information obtained through scraping empowers businesses to stay competitive and agile in a rapidly evolving market.
In conclusion, while scraping Amazon product data opens up a world of possibilities, it is imperative to approach this practice responsibly and ethically. By doing so, users can harness the immense potential of Amazon's vast repository of information for their specific needs, contributing to better decision-making and strategic growth.
Frequently Asked Questions

1. Why is scraping Amazon product data important?
Scraping Amazon product data provides valuable insights into product details, pricing, customer reviews, and more. This information can be crucial for informed decision-making, marketing strategies, and monitoring competitors.
2. What are the key considerations before scraping Amazon?
Before scraping, it's essential to adhere to Amazon's terms of service, practice responsible scraping to respect privacy and intellectual property, use a User-Agent header, employ proxy servers for anonymity, and develop strategies for CAPTCHAs and JavaScript challenges.
3. How do I set up a scraping environment for Amazon in Python?
You can set up a web scraping environment in Python by inspecting the web page, writing relevant scripts, handling pagination, and incorporating strategies to navigate through CAPTCHAs and JavaScript challenges.
4. How can businesses leverage scraped Amazon data?
Businesses can leverage scraped Amazon data for strategic decision-making, adjusting marketing strategies, monitoring competitors, analyzing trends, optimizing pricing, enhancing product offerings, and improving inventory management.
For further reading, you might be interested in the following: