Node.js is a preferred choice for web development and scraping due to its non-blocking architecture. Developers use Axios and Cheerio for static web pages and Puppeteer for dynamic ones.
Axios, a promise-based HTTP client, and Cheerio, a lightweight parsing library, work well for static web pages. Puppeteer, a headless browser automation library, is essential for dynamic content and JavaScript execution.
In essence, Node.js, with specialized libraries, empowers developers to create efficient web scraping solutions for both static and dynamic web pages.
So, let's delve into the world of Node.js web scraping and uncover the endless possibilities it offers.

What Is Node.js Web Scraping?
Node.js, a versatile runtime environment, has extended its capabilities beyond just building web applications to become a robust tool for web scraping.
This process involves extracting data from websites, and Node.js is particularly effective due to its ability to handle JavaScript, which is the backbone of many modern websites.
Scraping Static Web Pages
When it comes to scraping static web pages, these pages are simpler as they display their content without needing JavaScript to render it.
In such cases, Node.js can be used effectively by leveraging an HTTP client like Axios. This client helps download the HTML code of the targeted page.
Following the download, tools such as Cheerio come into play for parsing the HTML, allowing for extracting and organizing the required data.
Scraping Dynamic Web Pages
Dynamic web pages, on the other hand, are more complex as they rely on JavaScript to load their content. This is where Node.js truly shines, thanks to its compatibility with JavaScript.
To successfully scrape these types of pages, one needs to render the page fully, which is something traditional scraping scripts struggle with. This is where a headless browser like Puppeteer becomes indispensable.
It can navigate challenges like infinite scrolling or lazy loading, making Node.js an ideal choice for scraping modern websites and single-page applications.

The Advantages of Using Node.js for Web Scraping
When it comes to extracting data from JavaScript-heavy websites, such as social media platforms or news sites, Node.js emerges as a premier choice.
This runtime environment offers several compelling advantages for web scraping, setting it apart from other programming languages.
Also see: The 7 Best Programming Languages for Effective Web Scraping 2024
➡️ Superior Handling of Dynamic Websites
Node.js excels in scraping dynamic websites that are heavily reliant on JavaScript for content rendering. Its compatibility with JavaScript makes it a go-to option for navigating and extracting data from these types of sites efficiently.
➡️ Scalability and Performance
The non-blocking I/O model of Node.js enables the handling of numerous connections and requests simultaneously. This aspect is crucial for web scraping, especially when dealing with large volumes of data or multiple pages, as it ensures that performance does not degrade under heavy load.
➡️ Ease of Learning and Use
For those already familiar with JavaScript, Node.js presents a shallow learning curve. It often requires fewer lines of code compared to other languages capable of handling dynamic content, making it more accessible and quicker to implement.
➡️ Rich Library Ecosystem
Node.js boasts a vast array of libraries and frameworks accessible via the Node Package Manager (npm).
Noteworthy examples include Axios for HTTP requests and Puppeteer or Playwright for managing headless browsers. These tools are essential for handling complex tasks like JavaScript rendering, browser fingerprint spoofing, and circumventing anti-bot systems.
➡️ Extensive Community Support
The Node.js community is vast and active, offering an abundance of resources such as extensive documentation, tutorials, and forums like StackOverflow. This support network is invaluable for resolving specific issues and facilitating learning.
While Node.js is a powerhouse for scraping JavaScript-rendered websites, it's important to note that it might not be the most efficient choice for static websites, where languages like Python could require less code.
Crafting a Web Scraper Using Node.js- The Process

Step1: Determining the Need for a Headless Browser
Understanding when to employ a headless browser is crucial in the world of web scraping.
If the target website relies on dynamic elements and JavaScript-based fingerprinting techniques, a headless browser becomes indispensable.
However, for static content without such complexities, opting for a simpler HTTP client (e.g., Axios) and a parser (e.g., Cheerio) is more efficient.
Step 2: Selecting the Ideal Node.js Library
Puppeteer
Puppeteer, a potent headless browser designed primarily for web testing, also serves admirably in web scraping. It controls Chrome and Chromium browsers, utilizing Chromium’s DevTools Protocol for direct browser control. Puppeteer stands out for its speed and ease of use, making it a popular choice.
Playwright
Playwright emerges as a versatile cross-browser library for automation, supporting Chromium, Firefox, and WebKit. Its built-in driver eliminates the need for additional dependencies. Notably, Playwright's asynchronous nature allows seamless handling of multiple pages concurrently.
Selenium

Selenium remains a stalwart in web automation, especially for scraping dynamic websites. While it may be resource-intensive compared to Puppeteer and Playwright, Selenium boasts flexibility in terms of browser support and programming languages. Its longevity ensures solid community support.
Also see: Scrapy vs Selenium: Which Web Scraping Tool Wins?
Cheerio and Axios

Cheerio specializes in data parsing, transforming HTML code into a structured format. However, it lacks the ability to send requests, necessitating pairing with an HTTP client. Axios, the go-to HTTP client in Node.js, excels in making requests and can be seamlessly combined with Cheerio for a comprehensive web scraping experience.
Step 3: Planning the Web Scraping Project
Choosing Data Sources
When embarking on a web scraping project, consider whether to extract data from real targets like eBay or practice on designated scraping-friendly websites.
Seasoned users may opt for challenging sites, navigating through obstacles like CAPTCHAs. Alternatively, newcomers can hone their skills on dedicated web scraping sandboxes, ensuring a smoother learning curve.
Exploring API Endpoints
Look for API endpoints whenever possible. Some websites openly provide APIs, while others may have hidden endpoints discoverable through inspecting network requests. Reverse engineering an API endpoint can yield structured data with reduced bandwidth consumption.
For instance, GraphQL often serves as a valuable endpoint for handling substantial data in dynamic websites.
Respecting Website Policies
It is imperative to show respect for the websites being scraped. Thoroughly examine the robots.txt file to identify restricted pages.
Additionally, exercise caution to prevent server overload by minimizing the frequency of requests.
Employing proxies, especially rotating ones, helps conceal the scraper's real IP address and location, contributing to a more ethical and efficient scraping process.
Scraping Static Pages with Node.js (Using Axios and Cheerio)
Setting the Stage: Prerequisites
To embark on the journey of web scraping with Node.js, one must ensure that the latest version of Node.js is installed.
Additionally, two powerhouse libraries, Axios and Cheerio, serve as trusty companions for fetching and parsing data. Install them effortlessly with the following commands:
npm install axios
npm install cheerio
Library Imports for Seamless Scraping
The initial steps involve importing the essential libraries for a seamless scraping experience.
Axios, the robust Node.js HTTP client, is summoned alongside Cheerio, the versatile parser. The built-in Node.js file system module, denoted by 'fs', joins the ensemble for writing results into a CSV file.
import axios from 'axios'
import { load } from 'cheerio'
import fs from 'fs'
Crafting a Dynamic Exploration: Step by Step
1. Downloading the Page - Making a Request
The journey begins with downloading the target page. For this example, let's use the collection of books at books.toscrape.com. Fetch the page with Axios, and store the HTML response for further exploration.
const start_url = "http://books.toscrape.com/"
const books_list = []
let resp = await axios.get(start_url)
let resp_html = resp.data
const $ = load(resp_html)
2. Extracting Data - Parsing the HTML
To harmonize the web scraping symphony, the HTML is parsed using Cheerio. The parsing function meticulously extracts essential data points from the elements identified by the class "product_pod." Book titles, prices, ratings, stock information, and URLs are orchestrated into a structured list.
$('.product_pod').map((i, element) => {
const book_title = $(element).find('h3').text()
const book_price = $(element).find('.price_color').text().replace('£', '')
const book_rating = $(element).find('p.star-rating').attr("class").split(' ')[1]
const book_stock = $(element).find('.instock').text().trim()
const book_url = start_url + $(element).find('a').attr("href")
books_list.push({
"title": book_title,
"price": book_price,
"rating": book_rating,
"stock": book_stock,
"url": book_url
})
})
3. Saving Output to a CSV File
As the symphony nears its conclusion, the data is structured and written into a CSV file. The keys from the books object become the first line of the CSV file, and each book's information elegantly finds its place in subsequent lines.
function write_to_csv(){
var csv = Object.keys(books_list[0]).join(', ') + '\n'
books_list.forEach(function(book) {
csv += `"${book['title']}", ${book['price']}, ${book['rating']}, ${book['stock']}, ${book['url']},\n`
})
fs.writeFile('output.csv', csv, (err) => {
if (err)
console.log(err)
else {
console.log("Output written successfully")
}
})
}
4. Bringing it All Together
Initiate the scraping process by calling the functions in sequence. The script starts with the scrape function, and once the scraping is complete, the write_to_csv function is called.
await scrape(start_url)
write_to_csv()
Unleashing the Power of Node.js and Puppeteer: Scraping Dynamic Pages

Navigating the Dynamic Landscape
In this insightful guide, the focus shifts to dynamic pages, and the spotlight is on the dynamic duo - Node.js and Puppeteer. The mission? Extracting text, quotes, authors, and tags from two dynamic URLs at quotes.toscrape.com and quotes.toscrape.com/js-delayed/.
Both URLs present dynamic elements, with the latter incorporating delayed rendering, a valuable feature for scenarios where patience is key.
Setting the Stage: Prerequisites
Before diving into the dynamic world of web scraping, ensure that Node.js is seamlessly installed. Additionally, Puppeteer, the star of this dynamic performance, needs its entrance - install it effortlessly by referring to the official website.
npm install puppeteer
Library Imports for a Dynamic Symphony
The script commences by importing the necessary elements. Puppeteer takes center stage while the built-in Node.js file system module ('fs') and URLs are enlisted as supporting characters.
import puppeteer from 'puppeteer'
import fs from 'fs'
const start_url = 'http://quotes.toscrape.com/js/'
//const start_url = 'http://quotes.toscrape.com/js-delayed/'
Crafting a Dynamic Exploration: Step by Step
1. Dynamic Harmony: CSS Selectors and Setup
The dynamic journey kicks off by inspecting the page source and setting up CSS selectors to capture the essence of quotes.toscrape.com/js. These selectors include elements such as text, quote, author, tag, and the next page selector.
const quote_elem_selector = '.quote'
const quote_text_selector = '.text'
const quote_author_selector = '.author'
const quote_tag_selector = '.tag'
const next_page_selector = '.next > a'
2. Preparation for Dynamic Scraping
Puppeteer demands a grand entrance, requiring initiation in a headful mode. The prepare_browser function ensures the stage is set, launching Puppeteer with the necessary configurations.
async function prepare_browser() {
const browser = await puppeteer.launch({
headless: false,
})
return browser
}
3. Dynamic Exploration: Scraping Multiple Pages
The script facilitates dynamic exploration by defining the get_page function. It traverses through the URLs, patiently awaits the emergence of dynamic content, and smoothly transitions to the next page for a thorough dynamic scraping experience.
async function get_page(page, url) {
await page.goto(url)
await page.waitForSelector(quote_elem_selector, {timeout: 20_000})
await scrape(page)
try {
let next_href = await page.$eval(next_page_selector, el => el.getAttribute('href'))
let next_url = `https://quotes.toscrape.com${next_href}`
console.log(`Next URL to scrape: ${next_url}`)
await get_page(page, next_url)
} catch {
// Next page button not found, end job
return
}
}
4. Dynamic Parsing: Extracting Rich Content
The dynamic parsing unfolds in the scrape function. It elegantly navigates through quote elements, extracting text, authors, and tags dynamically.
async function scrape(page) {
let quote_elements = await page.$$(quote_elem_selector)
for (let quote_element of quote_elements) {
let quote_text = await quote_element.$eval(quote_text_selector, el => el.innerText)
let quote_author = await quote_element.$eval(quote_author_selector, el => el.innerText)
let quote_tags = await quote_element.$$eval(quote_tag_selector, els => els.map(el => el.textContent))
var dict = {
'author': quote_author,
'text': quote_text,
'tags': quote_tags,
}
quotes_list.push(dict)
}
}
5. Saving Output to CSV
The grand culmination of this dynamic process is the preservation of the output in a CSV file. The write_to_csv function meticulously structures the dynamic data, preparing it for future analysis.
function write_to_csv(){
var csv = Object.keys(quotes_list[0]).join(', ') + '\n'
quotes_list.forEach(function(quote) {
csv += `${quote['author']}, ${quote['text']}, "${quote['tags']}"\n`
})
fs.writeFile('output.csv', csv, (err) => {
if (err)
console.log(err)
else {
console.log("Output written successfully")
}
})
}
6. Bringing it All Together
The dynamic exploration concludes by harmonizing the entire performance. The main function coordinates the setup, scraping, and recording, bringing the dynamic exploration to a harmonious close.
async function main() {
var browser = await prepare_browser()
var page = await browser.newPage()
await get_page(page, start_url)
await browser.close()
console.log(quotes_list)
write_to_csv()
}
main()
In this exploration of dynamic web scraping with Node.js and Puppeteer, the script unveils the seamless extraction of content from dynamic pages, offering a glimpse into the intricacies of handling delayed rendering and dynamic elements.
Handling Asynchronous Operations
In the intricate choreography of web scraping, adeptly navigating asynchronous operations is tantamount to orchestrating a sophisticated performance.
As websites evolve to embody greater dynamism and interactivity, adeptly handling asynchronous tasks becomes imperative.
Promises in Node.js
Promises, akin to fundamental components in a script, imbue order into the asynchronous realm of Node.js. They furnish a methodical approach to managing asynchronous operations, ensuring the script seamlessly progresses while awaiting data retrieval.
Functioning as conductors, Promises regulate the flow of code, facilitating the graceful handling of both success and error scenarios.
Consider the scenario of soliciting data from a website through multiple requests. Promises diligently oversee each request concurrently, averting script stagnation and enabling the progression to subsequent operations even as others are underway.
Async/Await Syntax
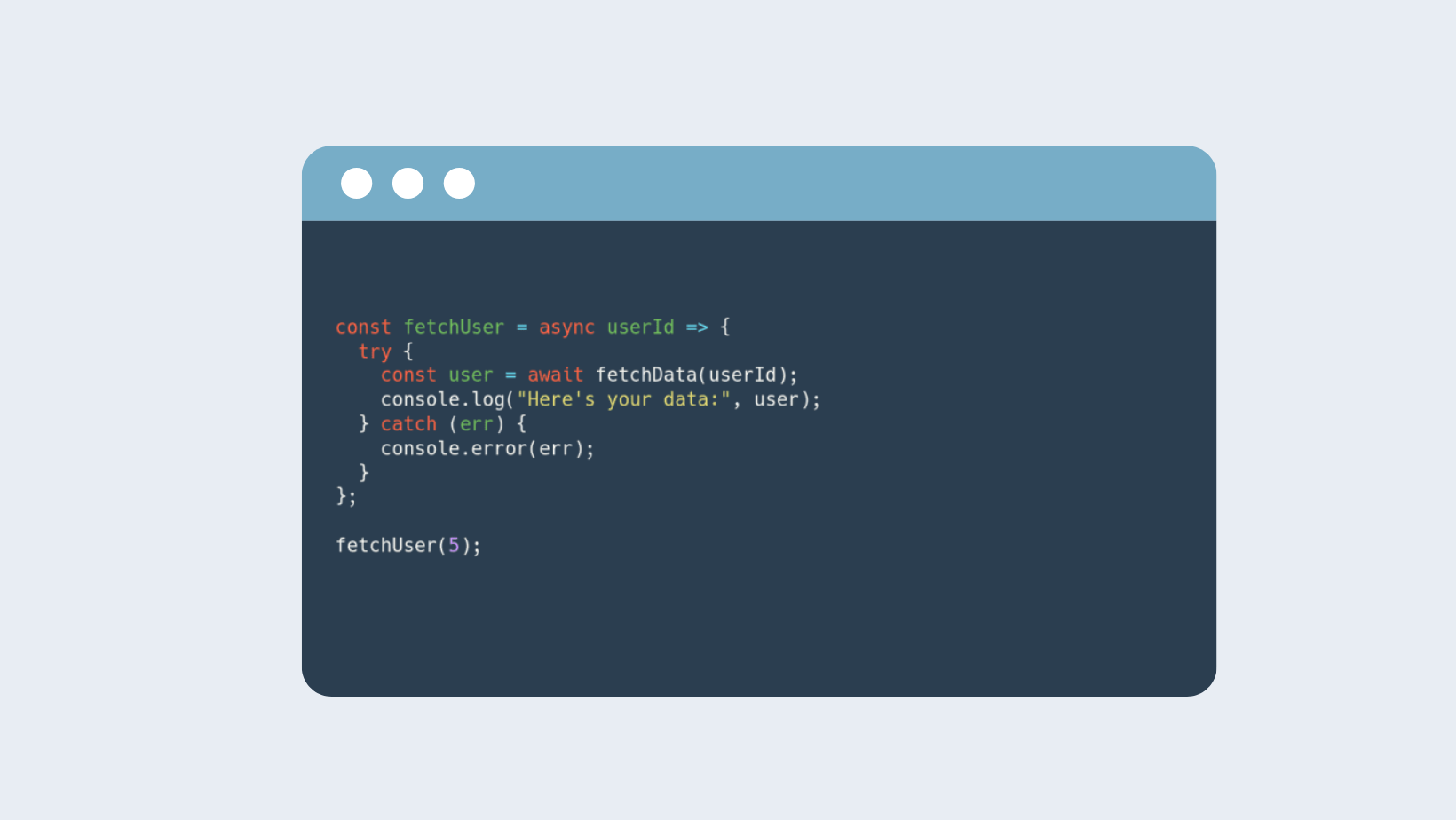
Introducing the Async/Await tandem—a syntactic refinement that imparts sophistication to your code. Async/Await simplifies the orchestration of Promises, presenting asynchronous code in a manner reminiscent of its synchronous counterpart. It resembles a virtuoso collaboratively melding with the ensemble, enhancing code legibility and maintainability.
With Async/Await, code structure mirrors the intuitive flow of synchronous operations, rendering it more comprehensible and troubleshoot-friendly. This syntactic coherence ensures the codebase remains lucid and concise, even in the face of intricate asynchronous tasks within the domain of web scraping.
Ensuring Sequential Execution in Dynamic Web Scraping
Dynamic web scraping is a domain where temporal precision holds paramount importance. Ensuring sequential execution marks the denouement of our intricate performance.
By judiciously employing Async/Await markers and harnessing Promises strategically, a script is assured to navigate seamlessly through the dynamic topography of the web.
Consider a scenario necessitating navigation across multiple pages or interaction with asynchronous loading elements. Sequential execution guarantees the completion of each step before advancing to the subsequent one, averting race conditions and fortifying the dependability of your web scraping script.

Combining Static and Dynamic Scraping
In the world of web scraping, versatility is key. Often, the data landscape is a mixed terrain of static and dynamic elements, each requiring a tailored approach for optimal extraction.
Knowing when to employ static or dynamic scraping techniques and seamlessly integrating both opens up a realm of possibilities for comprehensive data extraction.
Let's delve into the art of combining static and dynamic scraping to elevate your web scraping prowess.
Recognizing When to Use Each Approach
Understanding the nature of the website you're dealing with is the first step in the delicate dance of web scraping. Static websites, with their straightforward HTML structure, are like well-organized libraries where information is neatly stacked on shelves. They are perfect for simple, one-time data retrieval tasks.
Dynamic websites, on the other hand, are more like interactive playgrounds, with content changing dynamically through user interactions. When dealing with real-time updates, AJAX requests, or JavaScript-rendered pages, dynamic scraping becomes essential.
Recognizing when to use static scraping for stable, unchanging content and when to switch to dynamic scraping for real-time data is a skill that sets apart seasoned web scrapers.
Integrating Static and Dynamic Scraping Techniques
The synergy between static and dynamic scraping lies in their integration. Begin by statically scraping the stable, foundational data that forms the backbone of your information needs.
Once you have this base, transition seamlessly into dynamic scraping to capture the evolving elements that enrich your dataset. This combination ensures efficiency and accuracy as you harness the strengths of each technique.
Comprehensive Data Extraction
The true beauty of combining static and dynamic scraping lies in achieving comprehensive data extraction. Your goal is not just to gather data but to paint a vivid and detailed portrait of the website's content.
Static scraping provides the structure, while dynamic scraping adds the nuances and updates that breathe life into your dataset.
Conclusion
In summary, Node.js has emerged as a powerful choice for web scraping, accommodating both static and dynamic pages. The use of Axios and Cheerio facilitates scraping static content, while Puppeteer excels in handling dynamic elements.
Node.js proves its strength in handling JavaScript-heavy websites, offering scalability, superior performance, and an easy learning curve. The provided tutorials guide developers through the nuances of web scraping, emphasizing the importance of selecting the right tools for specific scenarios.
Whether using Axios and Cheerio for simplicity in static scraping or employing Puppeteer for dynamic challenges, Node.js empowers developers to efficiently extract data from the web. Its non-blocking architecture, rich library ecosystem, and community support make it a compelling choice in the world of web scraping.
Frequently Asked Questions
Why is Puppeteer used for scraping dynamic web pages in Node.js?
Puppeteer is a headless browser automation library that is essential for scraping dynamic pages. It can fully render pages with JavaScript, overcoming challenges like infinite scrolling or lazy loading, making it ideal for modern websites and single-page applications.
What are the advantages of using Node.js for web scraping?
Node.js offers superior handling of dynamic websites, scalability, ease of learning, a rich library ecosystem, and extensive community support. Its non-blocking I/O model ensures efficient handling of numerous connections simultaneously, making it suitable for handling large volumes of data.
What should be considered when planning a web scraping project in Node.js?
Consider the need for a headless browser based on the website's dynamics. Choose the right library (Puppeteer, Playwright, Selenium, Cheerio, and Axios) based on the project requirements. Respect website policies, explore API endpoints, and plan data sources accordingly.
Can Node.js be used for scraping static websites efficiently?
While Node.js is powerful for scraping JavaScript-rendered websites, it might not be the most efficient choice for purely static websites. In such cases, languages like Python could be more concise and require less code.