
Navigating the World Wide Web might seem like a Herculean task. The labyrinth of links can overwhelm even the most ambitious of users. If you've ever felt like you're descending into a bottomless pit of URLs when digging into a domain, you are not alone. But take heart! This article is here to light your path and guide you through the ins and outs of finding all URLs on a given domain.

We'll simplify the process and show you how this task is not as daunting as it seems. We’ll discuss various strategies, including the power of Google search, the utility of SEO tools like ScreamingFrog, and ways to craft your very own Python script. By the end, you'll be well-equipped with the knowledge and tools to confidently accomplish this task.
The Power of Unraveling URLs: Why It Matters
But what's the big fuss about finding all these URLs? Well, this endeavor holds remarkable importance:
- Content Scraping: Understanding the panoramic view of a website's content frames the big picture before launching an in-depth analysis. Hence, hunting URLs initiates this quest.
- Fixing Broken Links: A seamless user experience and robust SEO come from a well-oiled system of links. By finding all URLs, we can spot and fix any broken ones.
- Ensuring Google Visibility: Slow-loading or non-mobile-friendly pages can potentially impact your Google ranking adversely. A thorough check can reveal such issues for SEO improvement.
- Unearthing Hidden Pages: There might be pages overlooked by Google due to duplicate content or other related issues. Regular URL checks can help catch these elusive pages.
- Flagging Pages Google Shouldn't See: Certain webpages are created exclusively for internal use, like those under construction or meant for admins. Regular monitoring ensures these don't accidentally appear in search results.
- Refreshing Outdated Content: Keeping your content fresh is vital for Google rankings. Once you've laid out all your pages, strategizing updates and improvements becomes considerably easier.
- Improving Site Navigation: Identifying and eliminating orphan pages can enhance overall site navigation and credibility, making the user experience more intuitive and enjoyable.
- Competitor Analysis: An in-depth understanding of a competitor's website can offer invaluable insights to improve your own site.
- Website Redesign Preparation: Knowing the comprehensive layout of your pages aids in smoother website redesign processes.
Mastering the Art of Webpage Discovery: Techniques Unveiled
Unlocking the treasure of all webpages on a domain is no mean feat. Let's explore a variety of techniques, each with a unique approach to help you conquer this task.
The Google Search Method
- The humble Google search engine can serve as your first go-to method. Entering a distinctive query can help sift out all the pages of a website. However, it's crucial to remember that this method might not provide all the hidden jewels. Some pages may be missing, and occasionally, defunct pages might reflect in your search results.
Unearth with Sitemap and robots.txt
- For those unafraid of wading a little deeper into the technical waters, observing the website's sitemap and robots.txt file might reveal a wealth of URLs. This method could potentially be more accurate, but it comes with its challenges. If the website setup is flawed, sifting through this information could range from mildly annoying to Sisyphean.
SEO Spider Tools Marathon
- Keen on finding a simple solution that doesn't involve much technical legwork? Then SEO spider tools might be your forte. Multiple tools, each with unique characteristics, are available. While many are user-friendly and offer in-depth insights, a catch lies in the price tag they come with for extensive usage.
Custom Scripting Journey
- If you're familiar with coding and demanding specific outcomes, constructing a custom script can be your preferred path. Although it's the most involved method, it allows high customization and could yield the most comprehensive results. If you have the time and skills, a do-it-yourself script might perfectly fit your puzzle.
Walkthrough Tutorials: From Theory to Practice
Now that we're equipped with knowledge about different webpage discovery methods, it's time to shift gears into practical driving. Let's dive into hands-on tutorials for each strategy.
Estimating Page Count with Google Search
- Google's search engine can be a reliable partner for estimating your website's content.
First, head to google.com. Type in the search bar using the format: site:DOMAIN , replacing DOMAIN with your site's domain name, but leave off the https:// or http:// part. For example, site:www.webscraping.blog
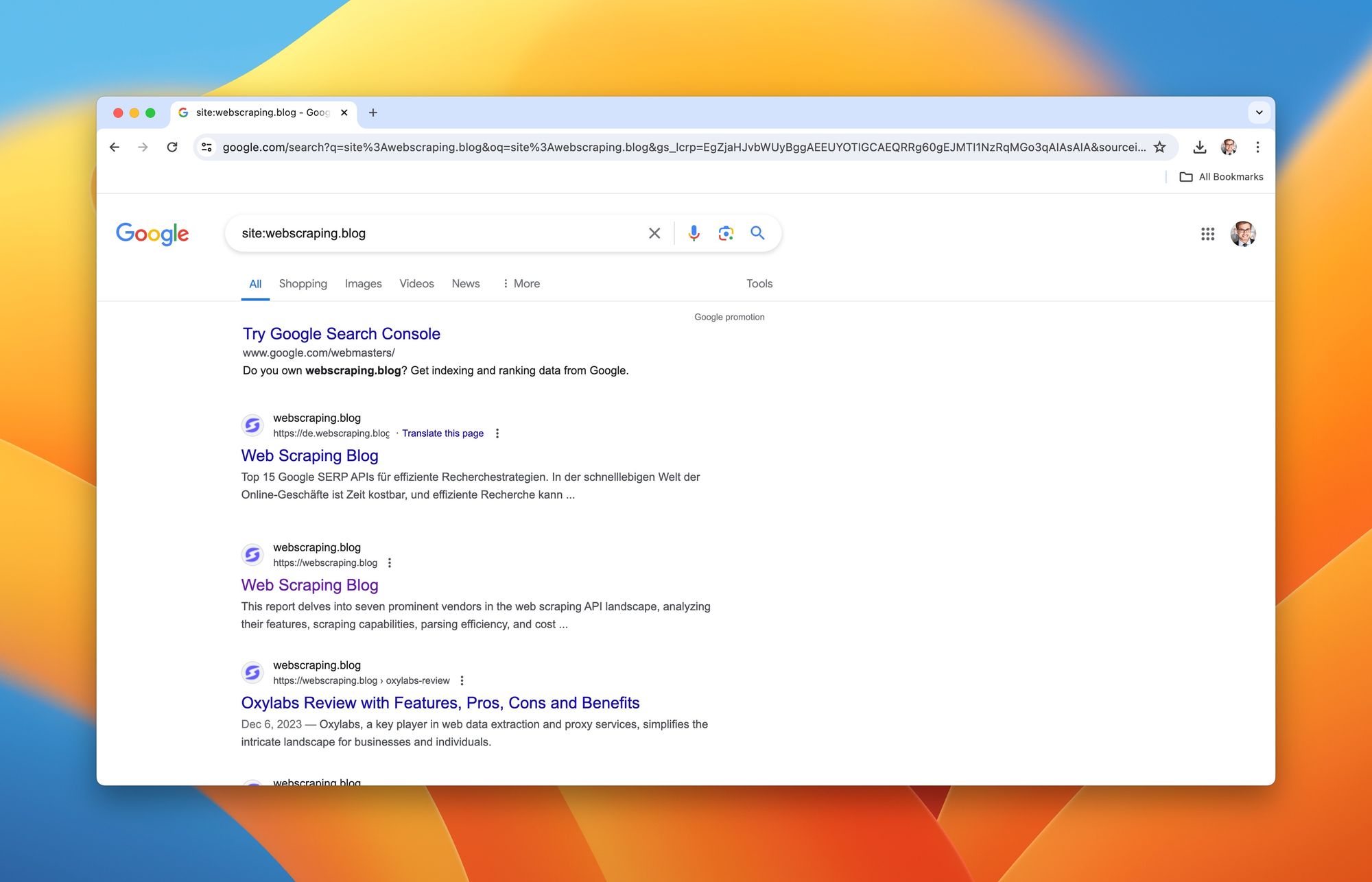
A list of indexed pages from your website will appear in the search results.
However, note that the mentioned number of results is an approximation. While this method is straightforward to give a general idea about your website's size, it might not be fully accurate due to Google's selective indexing process.
Scraping Tool for Google Search Results
ScrapingBee simplifies the task of manually analyzing Google's search results. As an efficient Google request builder tool, it organizes the search results in a simple, easy-to-analyze format.Navigate to Google API Request Builder:

Enter your desired search term into the Search box, and hit the 'Try it' button.
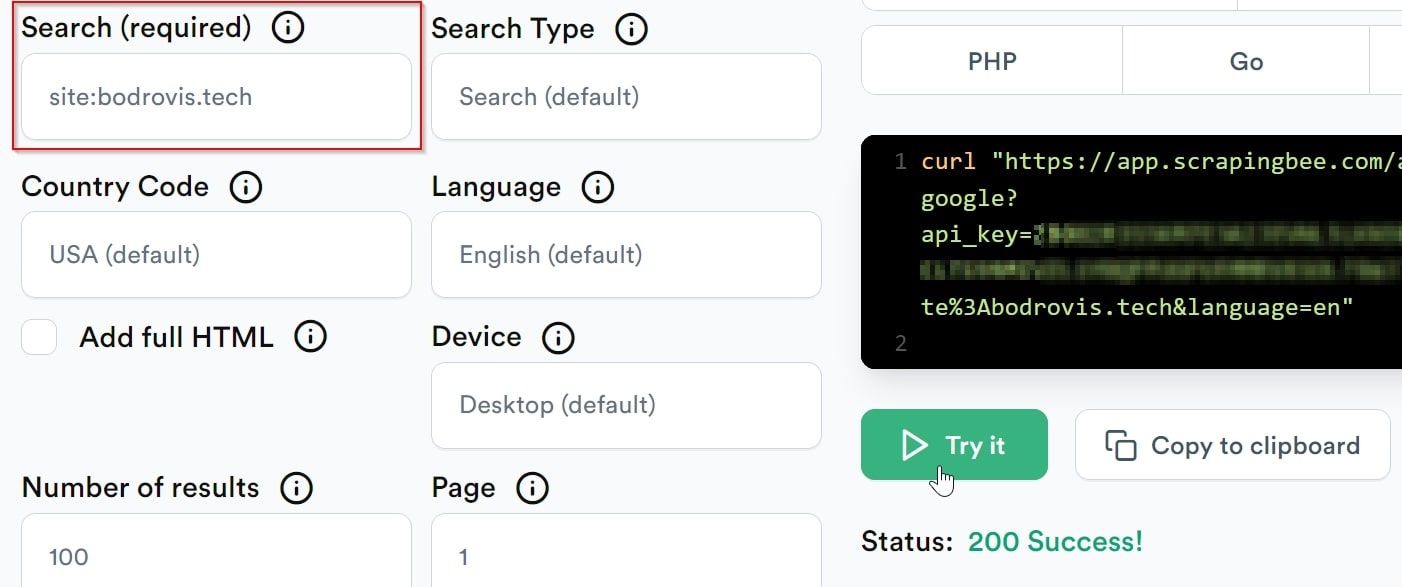
Your results will be presented in a neatly organized JSON format. Below is a sample showcasing the pertinent fields. Pay attention to the url keys which hold the actual webpage links:
"organic_results": [
{
"url": "https://bodrovis.tech/",
"displayed_url": "https://bodrovis.tech",
},
{
"url": "https://bodrovis.tech/en/teaching",
"displayed_url": "https://bodrovis.tech › teaching",
},
{
"url": "https://bodrovis.tech/ru/blog",
"displayed_url": "https://bodrovis.tech › blog",
}
]
Now you can simply download this JSON document and use it for your needs.
Uncovering All URLs Using Sitemaps and Robots.txt
Although this method may require more technical prowess, it's worth your efforts as it can yield more precise results. In this section, we'll explore how sitemaps and robots.txt files can guide us to map out all the URLs of a website.
Sitemaps
Website owners employ XML files referred to as "sitemaps" to aid search engines in comprehending and cataloging their websites better. Picture a sitemap as a blueprint offering invaluable understanding of the website's structure and material.
Here is an example of what a typical sitemap resembles:
COD
This XML format displays two URLs within the 'url' tag. Each 'loc' tag then uncovers the location of the respective URL. Extra data like the most recent modification date and alteration frequency are primarily leveraged by search engines.
For sitemaps of a smaller scale, manually copying the URLs from each 'loc' tag is doable. However, if you're dealing with larger sitemaps, the task can be considerably simplified by using an online tool that can convert XML into a more digestible format like CSV.
It's important to note that extensive websites might employ multiple sitemaps. In such cases, there's usually a primary sitemap that serves as a guide to additional, more specified sitemaps.
COD
Upon examining this file closely, it becomes clear that the site utilizes two sitemaps: one dedicated to English content, and another to French. You can then easily access each location to explore its specific content.
Locating Sitemaps
Unsure about where to find a sitemap? One suggestion would be to look for /sitemap.xml on the website, akin to https://example.com/sitemap.xml. The robots.txt file, which we'll inspect next, usually contains a sitemap link.
Here are some other typical sitemap locations you might find:
* /sitemap.xml.gz
* /sitemap_index.xml
* /sitemap_index.xml.gz
* /sitemap.php
* /sitemapindex.xml
* /sitemap.gz
* /sitemapindex.xml
Alternatively, you can also employ Google to aid you in this quest. Simply head to the Google search bar and type: site:DOMAIN filetype:xml. Remember to replace DOMAIN with the real domain of your website. This clever method is engineered to reveal a multitude of indexed XML files tied to your site, including the crucial sitemaps.
Bear in mind that if your website has a high concentration of XML files, some additional effort might be necessary to sift through everything. That said, don't stress—think of it as a mini-adventure on your path!
Utilizing robots.txt
The robots.txt is another file produced specifically for search engine use. It generally outlines the location of the sitemap, specifies which pages should be indexed, and mentions which ones should not be indexed. As per existing conventions, this file should be accessible under the /robots.txt path.
Here is a sample representation of what the robots.txt file looks like:
COD
In the given sample above, we can observe where the sitemap is situated. Additionally, there are several paths that have been explicitly disallowed from being indexed. This clearly indicates that these paths do exist on the site.
Crawling a Website Using ScreamingFrog
Now we'll shift our focus to utilizing an SEO spider to locate all the pages of a website. We'll engage the services of a tool named ScreamingFrog. Eager to test it out? Head to their official website and download the application to begin. They provide a complimentary version, well-suited for smaller sites, allowing you to explore up to 500 pages.
After you've downloaded it, launch the application (ensure it's in crawl mode), enter the URL of your website in the primary text field positioned at the top, and click on Start:

Allow for some time — particularly for more complex websites — and soon you will see an exhaustive list of URLs appearing right in front of you, directly from the ScreamingFrog results.
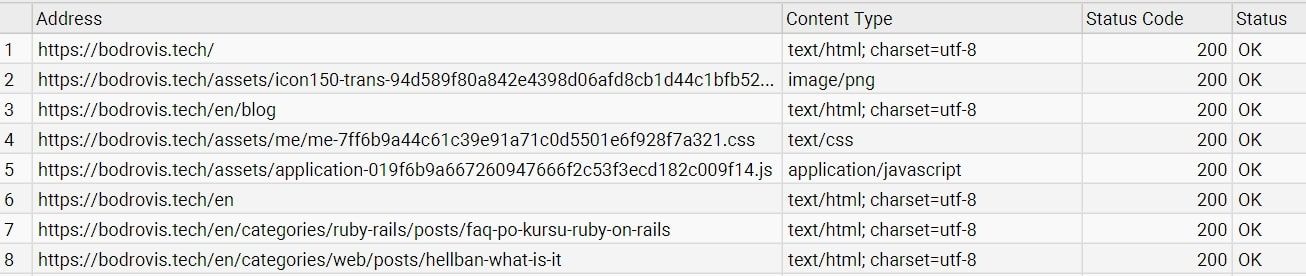
By default, it lists all elements, including images, JavaScript (JS), and Cascading Style Sheets (CSS) files. If your objective is solely to extract the main HTML pages, you can adjust the Filter option to streamline the results.
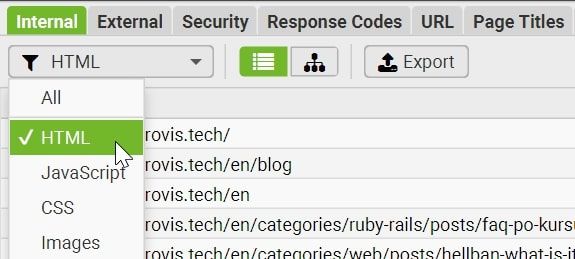
Additionally, you can employ the tabs positioned at the top to select the data you desire to view. For instance, this tool enables you to effortlessly identify broken links on your website.
Commencing with this tool is refreshingly straightforward. However, there might be instances where a site blocks your scraping sessions due to several potential reasons. If you encounter such roadblocks, you can experiment with a few solutions such as modifying the user agent or decreasing the number of threads at work. Navigate to the Configuration menu to make these adjustments.
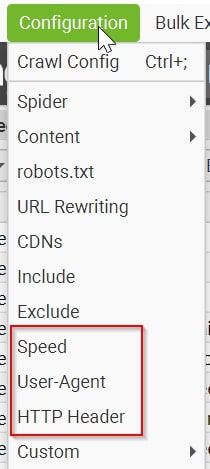
The key settings you'll likely focus more on adjusting would be the Speed, User-Agent, and HTTP Header options. However, remember that some of these advanced features might only be available in the paid version. Tweaking your user agent to "Googlebot (Smart Phone)" can often be helpful, though finding the optimal Speed might require some trial and error, as different websites have unique methods of detecting and blocking scrapers.
Also, within the "Crawl Config", it'd be advantageous to deselect "External links". This is because we're only interested in the links from our target website.
Crafting a Script to Identify All URLs on a Domain
In this segment, I'll walk you through creating a custom Python 3 script designed to fetch all URLs from a website.
First and foremost, let's initiate a new project employing Poetry:
'CODE'
Next, fortify your project's dependencies by appending the following lines to the pyproject.toml file:
'CODE'
Upon completion, execute the command:
'CODE'
If your choice does not include Poetry, you can merely install these libraries utilizing pip:
'CODE'
Subsequently, our next move involves opening the link_finder/link_finder.py file and importing the requisite dependencies:
'CODE'
We then proceed to send the request:
'CODE'
Now, let's devise a BeautifulSoup parser:
'CODE'
If upon executing this script you encounter an error intimating that the parser cannot be located, ensure the lxml library is installed:
'CODE'
Keep in mind, a sitemap file might point to more sitemaps that need to be addressed. We'll manage this via a recursive call:
'CODE'
Subsequently, we'll identify all the page URLs and prep the project root (since we'll be saving the URLs into a CSV file at a later stage):
'CODE'
Currently, the only task left is to loop through the URLs and store the data into a CSV file:
'CODE'
In this instance, I'm utilizing the ATTRS constant, so let's develop it:
'CODE'
This constant essentially illustrates which attributes should be extracted into the CSV file.
At this point, reaffirm our function's operation:
'CODE'
And there you have it! The final iteration of our script:
'CODE'
To execute it, simply call:
'CODE'
Strategies for Navigating Websites Sans Sitemap
Occasionally, you might encounter websites that forgo the standard sitemap route, a rarity in contemporary times. Nevertheless, it shouldn't dampen your spirits or halt your efforts. There's still a viable workaround!
Instead of focusing solely on the sitemap, you can initiate a scan on the main page of the website. This scan will reveal all the internal links present. Subsequently, you can add these newfound links into a queue and visit each of them leisurely, repeating the process till you've unearthed all the links. While all pages might not be linked, this strategy provides a thorough map of the entire website with minimal chances of missing out on content-filled corners.
To facilitate ease in this process, consider the following sample code:
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
class Crawler:
def __init__(self, urls=[]):
self.visited_urls = []
self.urls_to_visit = urls
def download_url(self, url):
return requests.get(url).text
def get_linked_urls(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for link in soup.find_all('a'):
path = link.get('href')
if path and path.startswith('/'):
path = urljoin(url, path)
yield path
def add_url_to_visit(self, url):
if url not in self.visited_urls and url not in self.urls_to_visit:
self.urls_to_visit.append(url)
def crawl(self, url):
html = self.download_url(url)
for url in self.get_linked_urls(url, html):
self.add_url_to_visit(url)
def run(self):
while self.urls_to_visit:
url = self.urls_to_visit.pop(0)
try:
self.crawl(url)
except Exception:
print(f'Failed to crawl: {url}')
finally:
self.visited_urls.append(url)
if __name__ == '__main__':
Crawler(urls=['https://www.example.com/']).run()- The list of URLs that we need to visit is maintained in an array named 'urls_to_visit'.
- All the hrefs on the webpage are recognized.
- If we come across a URL that hasn't been visited yet, we include it in the array.
- The script continues to run until there are no URLs remaining for visitation.
This code sets a solid baseline. However, for a more comprehensive solution, you can check out our Scrapy tutorial.
This code sets a solid baseline. However, for a more comprehensive solution, you can check out Scrapy tutorial.
Leveraging ScrapingBee for Sending Requests
This is where ScrapingBee proves its worth as it offers a Python client dedicated to sending HTTP requests. This client equips you with the ability to utilize proxies, acquire screenshots of the HTML pages, and modify cookies, headers, and more.
To commence, run pip install scrapingbee or incorporate it into your pyproject.toml to install the client:
'COD'
Next, integrate it into your script and instantiate the client:
'COD'
You can now make a request with the client, adjusting the parameters as desired:
'COD'
You're good to proceed with passing the response.content to BeautifulSoup as done earlier and use it to identify all the 'loc' tags inside.
Putting Your Newfound URLs into Action
So, you've meticulously gathered a treasure trove of URLs. What's next? How you utilize this bounty completely depends on your course of action.
If your compass points towards scraping data from these pages, you're about to venture into a rich landscape brimming with resources. The following articles are filled with invaluable insights and techniques for robust data extraction:
- Extracting Data from Websites - An in-depth exploration of various strategies for easy and efficient website data extraction.
- Best Web Scraping Tools for 2024 - Your guide to the cream of the crop when it comes to web scraping tools.
- Web Scraping with Python - Master the art of scraping with Python, one of the most popular languages for data extraction.
- Web Scraping with Scrapy- Diving into the world of Scrapy, a Python-powered tool, for efficient data extraction.
- Circumventing Blockades in Web Scraping - Strategies for successful scraping escapades minus the hindrance of blocks and bans.
- Thread-by-Thread Guide to Web Crawling with Python - How to build your Python crawler from scratch.
- Web Scraping with JavaScript and NodeJS - A guide to web scraping using the power of JavaScript and NodeJS.
Take a leap with ScrapingBee API for a swift and smooth data scraping journey. No more grappling with headless browsers, dodging rate limits, shuffling through proxies, or wrestling with captchas. Focus on the prime objective: the data. Let us handle the behind-the-scenes details, while you convert the raw information into meaningful insights.
Wrapping Up
We've journeyed together from the whys and wherefores of uncovering all URLs on a domain, untangled a variety of techniques, stretched the possibilities with hands-on tutorials, and anchored ourselves with strategies for websites without a sitemap. In the end, we illuminated the actions you can take with the amassed URLs.
This comprehensive guide intended to equip you with diverse resources and tools for your webpage discovery endeavors. Armed with these methods and strategies, discovering all the webpages of a domain should no longer be a daunting task.
Once again, thank you for joining me on this expanse of website exploration. Now, it's your turn to brave the waves and embark on your unique scraping ventures. May your data hunting be fruitful and insightful!
Frequently Asked Questions (FAQs)
What are the benefits of detecting all URLs on a domain?
- There are several advantages such as scraping website's content, fixing broken links, assessing Google visibility, discovering hidden or outdated pages, improving site navigation, performing competitor analysis, and aiding in website redesigns.
What are some popular methods to find all webpages on a domain?
- A Google search, checking the website's sitemap and robots.txt file, using SEO spider tools, and creating custom scripts are among the common methods.
How can Google search reveal a website's page count?
- Typing "site:YOURDOMAIN.com" (replace "YOURDOMAIN.com" with your site's domain name) in Google's search bar will display a list of indexed pages from your website. Please keep in mind, Google may not discover every page, and the count may include outdated pages.
What does ScrapingBee do?
- ScrapingBee is a Google request builder tool that arranges search results in a neat, easy-to-analyze format. It saves time that would be spent manually analyzing search results.
What is ScreamingFrog, and how can it help find webpages?
- ScreamingFrog is an SEO tool that can comprehensively crawl a website to provide a list of all its URLs.
Can I still locate all URLs if a website doesn't have a sitemap?
- Yes. By scanning the main page of the website and identifying all internal links, you can put these links into a queue, visit each link, and repeat the process until you've tracked all pages.
What can I do with the URLs once I've found them?
- The next course of action depends on your objectives. If your goal is to scrape data from these pages, there are numerous resources available to guide you through this process. Techniques associated with Python, Scrapy, JavaScript, and NodeJS, for instance, can be beneficial for data scraping.
What kind of information can I find in a sitemap?
- A sitemap file, generally in XML format, can give you a bird's eye view of a website’s structure. It lists all the URLs within the site, often including details like when each page was last updated, how frequently changes are made, and how important each page is in relation to other pages on the site.
Can I use Google to find a website's sitemap?
- Yes, a quick way is to type "site:YOURDOMAIN.com filetype:xml" in the Google search bar, replacing "YOURDOMAIN.com" with the website's domain. The search results may yield a list of indexed XML files linked to the website, including the sitemaps.
How does a Python script help in finding all URLs on a domain?
- Utilizing Python, you can create a custom script to automatically request and parse a website's sitemap, returning a comprehensive list of URLs listed in the sitemap. This can be particularly useful for large websites with more extensive URL lists.