
Using proxies with Python's Requests library is essential for web scraping and dealing with websites that employ anti-bot measures.
The Requests library, known for its ease of use and efficiency, becomes even more powerful with proper proxy configuration.
This guide will help you understand how to set up and rotate proxies using Python Requests, ensuring your web scraping activities remain uninterrupted.

Why Use Proxies with Python Requests?
When working with web scraping, API requests, or any online data retrieval tasks using Python, incorporating proxies into your workflow becomes not just an option but a strategic necessity.
Proxies, or intermediary servers that stand between your client and the target server, offer a range of benefits that significantly enhance the robustness and effectiveness of your Python Requests-based projects.
Also see: The 7 Best Programming Languages for Effective Web Scraping 2024

1. Anonymity and Privacy:
Proxies act as a shield, masking your true IP address and identity from the target server. This anonymity is crucial when dealing with websites that might block or limit access based on IP addresses.
By using proxies, you can conduct your data retrieval activities without revealing your original identity.
2. Bypassing Restrictions:
Many websites implement access restrictions based on IP addresses, geographical location, or other factors.
Proxies enable you to circumvent these restrictions by making requests through servers located in different regions or countries. This is particularly valuable when dealing with geo-restricted content or when a website imposes rate limits on requests.
3. Distributing Requests:
Distributing your requests across multiple proxies can help distribute the load, preventing your IP from being flagged for excessive activity. This is especially important when dealing with web scraping tasks or making numerous API requests.
By spreading requests across different IP addresses, you reduce the risk of being blocked or rate-limited.
4. Avoiding IP Blocking:
Websites often employ security measures that automatically block IP addresses exhibiting suspicious behavior, such as a high volume of requests in a short period. Proxies provide a way to rotate and change your IP address, making it difficult for websites to track and block your activities.
5. Scalability:
Proxies offer a scalable solution for handling large-scale data extraction projects. Whether you are scraping data from multiple sources or making extensive API calls, proxies allow you to scale your operations without overburdening a single IP address.
6. Protecting Your Infrastructure:
By using proxies, you add an extra layer of protection to your local infrastructure. Rather than exposing your servers directly to the internet, requests are sent through the proxy, reducing the risk of potential security threats and attacks.
7. Compliance with Terms of Service:
Many websites and online platforms have terms of service that dictate how their data can be accessed and used. Proxies enable you to adhere to these terms by providing a mechanism to make requests in a manner that aligns with the website's policies, ensuring compliance and ethical data usage.

Setting Up Proxies in Python Requests
Prerequisites
- Python 3: Ensure you have the latest version of Python installed.
- Requests Library: Install it using
pip install requests. - Code Editor: Choose any code editor that you prefer.
Basic Configuration Steps
1. Initialize Python Requests:
import requests
2. Add Proxy Information:
For an HTTP proxy:
proxies = {
'http': 'http://host:PORT',
'https': 'http://host:PORT',
}
For a SOCKS5 proxy:
proxies = {
'http': 'socks5://host:PORT',
'https': 'socks5://host:PORT',
}
3. Create a Response Variable:
Pass the proxies parameter in the request method.
response = requests.get('URL', proxies=proxies)
Proxy Authentication
To authenticate your proxy, include the username and password in the proxy configuration:
proxies = {
'http': 'http://user:password@host:PORT',
'https': 'http://user:password@host:PORT',
}
response = requests.get('URL', proxies=proxies)
Setting Up Proxy Sessions
For multiple requests with the same proxy:
session = requests.Session()
session.proxies = proxies
response = session.get('URL')
Setting Up Environment Variables
Set/Export Environment Variables:
- Windows:
set http_proxy=http://username:password@:PORT
set https_proxy=http://username:password@:PORT
- Linux:
export http_proxy=http://username:password@:PORT
export https_proxy=http://username:password@:PORT
Use Environment Variables in Code:
import os
proxies = {
'http': os.environ['http_proxy'],
'https': os.environ['https_proxy']
}
requests.get('URL', proxies=proxies)
Testing Proxies
Once you've chosen and implemented proxies with Python Requests, it's essential to verify their functionality and reliability.
Testing proxies ensures that they meet your requirements, operate as expected, and contribute to the overall success of your web scraping or API requests.
Here are key aspects to consider when testing proxies:

1. Verifying Proxy Connectivity:
Before integrating proxies into your Python Requests, confirm that you can establish a connection to the proxy server.
Use a simple script to send a test request through the proxy and check for successful responses.
This step ensures that your Python environment can communicate with the chosen proxies.
import requests
proxy = {
'http': 'http://your_proxy_address',
'https': 'https://your_proxy_address',
}
try:
response = requests.get('https://www.example.com', proxies=proxy)
print(response.status_code)
except requests.RequestException as e:
print(f"Error: {e}")
2. Checking for IP Leaks:
Proxies should effectively mask your original IP address. Use online tools or services that display your IP address to confirm that requests made through the proxy are indeed using the proxy's IP and not leaking your actual IP address. This step ensures the anonymity and privacy benefits of using proxies.
3. Testing Speed and Latency:
Evaluate the speed and latency of your proxy connections, as this directly impacts the performance of your Python Requests. You can measure response times for requests made through proxies and compare them to direct requests without proxies. Opt for proxies that provide a balance between speed and reliability.
4. Handling Proxy Rotation:
If you plan to rotate proxies to avoid detection or bypass rate limits, implement and test a rotation mechanism. Confirm that the rotation works seamlessly without disrupting the flow of your Python Requests. This is crucial for long-running scraping tasks or extensive API interactions.
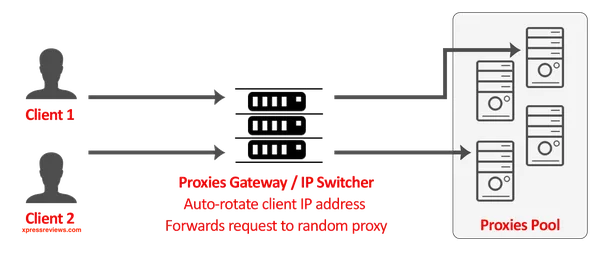
5. Monitoring Request Limits:
Some proxies may have usage limits or restrictions. Keep track of the number of requests you make through each proxy and monitor for any limitations imposed by the proxy provider. Adjust your scraping or API strategy accordingly to stay within acceptable usage limits.
6. Ensuring Reliability:
Proxies may occasionally go offline or experience issues. Implement error-handling mechanisms in your Python script to gracefully handle situations where the proxy becomes unavailable. This ensures the reliability and robustness of your data retrieval process.
7. Testing Different Proxy Types:
Depending on your use case, you might be working with HTTP, HTTPS, or SOCKS proxies. Test the compatibility and effectiveness of each proxy type for your specific application. Ensure that your Python Requests configuration aligns with the proxy type you are using.
Best Practices
When working with proxies in Python Requests, implementing best practices ensures a smoother and more reliable data retrieval process. Consider the following guidelines to optimize your workflow:
Rotating Proxies
Rotating proxies is a key strategy to prevent IP blocking, distribute requests, and maintain anonymity. Implement a rotation mechanism to switch between different proxies at regular intervals. This helps in:
Circumventing Rate Limits: If a website enforces rate limits per IP address, rotating proxies can help distribute requests, allowing you to stay within acceptable limits.
Enhancing Anonymity: Regularly changing proxies adds an extra layer of anonymity, making it challenging for websites to trace and block your activities.
Rotating proxies is a key strategy for avoiding blacklisting or rate limiting by websites during web scraping or data collection processes. Here's a guide on how to efficiently rotate proxies using Python's Requests library.
How to Rotate Proxies with Python Requests
1. Choose Quality Proxies: It's advisable to opt for paid proxy services over free ones. Paid proxies are more reliable, secure, and less likely to get blocked.
2. Import Necessary Libraries:
import requests
import random
3. Define Your Proxy Pool:
Create a list of IP addresses to rotate.
proxy_pool = ['user:password@host:3001', 'user:password@host:3002', 'user:password@host:3003']
4. Iterate Through Requests:
Go through a set number of requests (e.g., 10 requests in this example).
for i in range(10):
5. Select a Random Proxy:
Choose a proxy randomly from your pool for each request.
proxy = {'http': random.choice(proxy_pool)}
6. Send the Request Using the Selected Proxy:
response = requests.get('URL', proxies=proxy)
7. Print the Response:
Display the response text for each request.
print(response.text)
Full Script for Proxy Rotation
import requests
import random
# Define your proxies
proxy_pool = ['user:password@host:3001', 'user:password@host:3002', 'user:password@host:3003']
# Going through 10 requests
for i in range(10):
# Select a random proxy from the pool
proxy = {'http': random.choice(proxy_pool)}
# Send the request using the same proxy
response = requests.get('URL', proxies=proxy)
# Print the response
print(response.text)
Error Handling and Retry Mechanisms
Proxy connections may occasionally fail due to network issues or other transient problems.
Retrying Failed Requests: When a request through a proxy fails, configure your script to retry the request with the same or a different proxy to account for temporary issues.
Logging Errors: Log detailed error messages to aid in debugging. This information helps identify specific issues with proxies and facilitates troubleshooting.
Example of Error Handling and Retry in Python Requests:
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
# Configure retry strategy
retry_strategy = Retry(
total=3,
status_forcelist=[429, 500, 502, 503, 504],
method_whitelist=["HEAD", "GET", "OPTIONS"]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
# Create a session with the adapter
session = requests.Session()
session.mount('http://', adapter)
session.mount('https://', adapter)
# Make a request with error handling and retry
try:
response = session.get('https://www.example.com', proxies={'http': 'http://your_proxy_address'})
response.raise_for_status()
print(response.content)
except requests.RequestException as e:
print(f"Error: {e}")
Monitoring Request Limits
Proxies may have limitations on the number of requests allowed within a specific time frame. Monitor and manage request limits to avoid disruptions to your data retrieval process:
Regularly Check Usage: Periodically check your usage against the allowed limits to ensure compliance. Adjust your script accordingly if you approach or exceed these limits.
Implement Throttling: Introduce throttling mechanisms to regulate the rate of requests and prevent surpassing proxy limits.
Example of Monitoring Request Limits:
import time
import requests
proxy = {'http': 'http://your_proxy_address'}
# Set the desired request rate
requests_per_minute = 60
delay = 60 / requests_per_minute
while True:
try:
response = requests.get('https://www.example.com', proxies=proxy)
response.raise_for_status()
print(response.content)
except requests.RequestException as e:
print(f"Error: {e}")
time.sleep(delay)
By incorporating these best practices, you ensure the effectiveness, reliability, and longevity of your Python Requests-based projects while working seamlessly with proxies.
Examples and Use Cases
Explore practical examples and use cases demonstrating the application of proxies with Python Requests for web scraping, API requests, and bypassing geo-restrictions:
Web Scraping with Proxies
Web scraping often involves extracting data from websites, and proxies play a crucial role in enhancing the process:
1. Setting Up Proxies for Web Scraping:
Configure Python Requests to use proxies for web scraping tasks. This example demonstrates scraping a simple webpage with a rotating proxy.
import requests
from itertools import cycle
proxy_list = ['http://proxy1.example.com', 'http://proxy2.example.com', 'http://proxy3.example.com']
proxy_pool = cycle(proxy_list)
for i in range(5):
proxy = next(proxy_pool)
try:
response = requests.get('https://www.example.com', proxies={'http': proxy, 'https': proxy})
print(f"Proxy {proxy}: {response.status_code}")
# Parse and process the webpage content here
except requests.RequestException as e:
print(f"Error with proxy {proxy}: {e}")
2. Handling Captchas with Proxies:
In cases where web scraping encounters captchas, rotating proxies can be used to bypass restrictions by switching to a new IP address.
import requests
import time
proxy = {'http': 'http://your_proxy_address'}
try:
response = requests.get('https://www.example.com', proxies=proxy)
if "captcha" in response.text.lower():
# Switch to a new proxy or wait for a while before retrying
time.sleep(60)
response = requests.get('https://www.example.com', proxies=proxy)
print(response.content)
except requests.RequestException as e:
print(f"Error: {e}")
Making API Requests through Proxies
Proxies are valuable when interacting with APIs, ensuring reliability, and preventing rate limiting:
1. Configuring Proxies for API Requests:
Integrate proxies seamlessly into your Python script for making API requests. This example demonstrates sending a request to a hypothetical API using a proxy.
import requests
api_url = 'https://api.example.com/data'
proxy = {'http': 'http://your_proxy_address'}
try:
response = requests.get(api_url, proxies=proxy)
response.raise_for_status()
# Process API response here
print(response.json())
except requests.RequestException as e:
print(f"Error: {e}")
2. Handling API Key Usage with Proxies:
When working with APIs that require authentication, proxies can be employed to manage API key usage effectively.
import requests
api_url = 'https://api.example.com/data'
proxy = {'http': 'http://your_proxy_address'}
headers = {'Authorization': 'Bearer YOUR_API_KEY'}
try:
response = requests.get(api_url, proxies=proxy, headers=headers)
response.raise_for_status()
print(response.json())
except requests.RequestException as e:
print(f"Error: {e}")
Bypassing Geo-Restrictions
Proxies enable users to access content restricted based on geographical location:
1. Accessing Geo-Restricted Content:
Use a proxy to access content that is restricted to specific regions. This example demonstrates accessing a website with geo-restricted content using a proxy.
import requests
geo_restricted_url = 'https://www.example-geo-restricted.com'
proxy = {'http': 'http://proxy_in_target_region'}
try:
response = requests.get(geo_restricted_url, proxies=proxy)
response.raise_for_status()
# Process the geo-restricted content here
print(response.content)
except requests.RequestException as e:
print(f"Error: {e}")
2. Streaming Geo-Restricted Media:
Proxies can be used to access geo-restricted media content, allowing users to stream content from different geographical locations.
import requests
geo_restricted_media_url = 'https://stream.example.com/video'
proxy = {'http': 'http://proxy_in_desired_region'}
try:
response = requests.get(geo_restricted_media_url, proxies=proxy, stream=True)
response.raise_for_status()
# Stream the geo-restricted media content here
for chunk in response.iter_content(chunk_size=8192):
print(chunk)
except requests.RequestException as e:
print(f"Error: {e}")
By applying these examples and use cases, you can leverage proxies effectively in your Python Requests-based projects, enhancing your ability to scrape data, interact with APIs, and access geo-restricted content seamlessly.
Conclusion
In summary, integrating proxies with Python Requests is essential for enhancing the robustness, privacy, and scalability of web scraping and API request projects.
Proxies provide anonymity, bypass restrictions, and distribute requests, contributing to project scalability and infrastructure protection. The guide covers key steps, best practices, and testing procedures, emphasizing the significance of proxy rotation.
By following these guidelines, Python Requests projects can navigate anti-bot measures, comply with website policies, and achieve reliable and scalable data retrieval. Proxies are not just a technical necessity but a strategic tool for seamless and ethical online activities.
Frequently Asked Questions
Why is it important to use proxies with Python Requests for web scraping?
Web scraping often involves making numerous requests to a website, which may lead to IP blocking or other restrictions. Proxies provide anonymity, distribute requests, and help avoid detection, ensuring uninterrupted data retrieval. They also enhance privacy by masking the original IP address.
How do I rotate proxies in Python Requests, and why is it necessary?
Rotating proxies involves switching between different IP addresses to prevent being blocked by websites or encountering rate limits. This is crucial for long-running scraping tasks.
How do I set up proxies in Python Requests?
To set up proxies in Python Requests, you need to initialize the library, add proxy information using either HTTP or SOCKS5 configurations, and pass the proxies parameter in the request method. For proxy authentication, include the username and password in the proxy configuration. You can also set up proxy sessions for multiple requests and use environment variables for configuration.
For further reading, you might be interested in the following: